library(sf)
library(stars)
library(tmap)
library(raster)
library(plotly)
library(mapview)
library(tidyverse)
library(ggrepel)
library(dismo) # библиотека species distribution modelling
library(akima) # библиотека для интерполяции на основе триангуляции
library(gstat) # библиотека для геостатистической интерполяции, построения трендов и IDW
library(deldir) # библиотека для построения триангуляции Делоне и диаграммы Вороного
library(fields) # радиальные базисные функции (сплайны минимальной кривизны)
library(MBA) # иерархические базисные сплайны
# Убираем экспоненциальное представление больших чисел
options(scipen=999)
db = "data/italy.gpkg"
# Читаем слои картографической основы
cities = st_read(db, 'cities') %>% # Города
bind_cols(st_coordinates(.) |> as_tibble())
## Reading layer `cities' from data source
## `/Users/tsamsonov/GitHub/r-geo-course/data/italy.gpkg' using driver `GPKG'
## Simple feature collection with 8 features and 37 fields
## Geometry type: POINT
## Dimension: XY
## Bounding box: xmin: 368910.4 ymin: 4930119 xmax: 686026 ymax: 5115936
## Projected CRS: WGS 84 / UTM zone 32N
rivers = st_read(db, 'rivers') # Реки
## Reading layer `rivers' from data source
## `/Users/tsamsonov/GitHub/r-geo-course/data/italy.gpkg' using driver `GPKG'
## Simple feature collection with 23 features and 10 fields
## Geometry type: MULTILINESTRING
## Dimension: XY
## Bounding box: xmin: 332178.5 ymin: 4922880 xmax: 758033.3 ymax: 5121416
## Projected CRS: WGS 84 / UTM zone 32N
lakes = st_read(db, 'lakes') # Озера
## Reading layer `lakes' from data source
## `/Users/tsamsonov/GitHub/r-geo-course/data/italy.gpkg' using driver `GPKG'
## Simple feature collection with 6 features and 13 fields
## Geometry type: POLYGON
## Dimension: XY
## Bounding box: xmin: 460686.2 ymin: 4938750 xmax: 757443.7 ymax: 5113557
## Projected CRS: WGS 84 / UTM zone 32N
# Читаем ЦМР — цифровую модель рельефа на регулярной сетке
dem = read_stars("data/gtopo.tif")
# Читаем данные об осадках
pts = read_table2("data/Rainfall.dat") %>%
st_as_sf(coords = c('x', 'y'),
crs = st_crs(cities),
remove = FALSE)
# Координаты пригодятся нам в дальнейшем
coords = st_coordinates(pts)15 Интерполяция геополей
В лекции рассмотрены детерминистические методы восстановления непрерывных поверхностей по данным в точках. Детерминистические методы интерполяции производят интерполяцию значений на основе заданной аналитической зависимости между значением в точке и значениями в пунктах с исходными данными. Это отличает их от методов геостатистических, где эта зависимость находится статистическим путем. Геостатистические методы будут рассмотрены далее.
15.1 Введение
Интерполяция в общем случае — это способ нахождения промежуточных значений величины по имеющемуся дискретному набору известных значений. В географии обычно имеют дело с двумерным случаем интерполяции — когда измерения проведены в некоторых географических локациях, и по ним нужно восстановить непрерывную картину поля распределения величины. В общем случае неизвестно, как ведет себя исследуемое явление между точками, поэтому существует бесчисленное множество вариантов интерполяции.
Методы которые производят интерполяцию на основе заданной аналитической зависимости, называют детерминистическими. Параметры этой зависимости могут быть как априори заданы пользователем, так и определяться автоматически одним из методов оптимизации — в частности, по методу наименьших квадратов.
Например, мы можем сказать, что между соседними точками показатель меняется линейным образом (здесь нужно еще указать, что мы понимаем под соседством). Такие методы достаточно просты в использовании и интерпретации. В то же время, они не учитывают статистических особенностей поведения величины между точками, которое определяется ее автокорреляционными свойствами. Методы интерполяции, которые учитывают пространственную автокорреляцию, называют геостатистическими. Они более сложны в использовании, но потенциально могут дать более достоверные результаты.
В этом модуле мы познакомимся со следующими детерминистическими методами интерполяции.
- Метод ближайшего соседа (nearest neighbor)
- Метод естественного соседа (nearest neighbor)
- Метод интерполяции на основе триангуляции
- Метод обратно взвешенных расстояний (ОВР)
- Метод радиальных базисных функций (РБФ)
- Метод иерархических базисных сплайнов (ИБС)
Интерполяцию будем рассматривать на примере данных по количеству осадков на метеостанциях в северной Италии (долина реки По и окружающие горы). Станции распределены в пространстве нерегулярно, что позволит визуально оценить чувствительность методов к этому фактору.
Прежде чем исследовать распределение показателя, необходимо проанализировать географический контекст. В этой части модуля мы воспользуемся уже известными функциями чтобы создать карту с общегеографической основой и нанести на нее пункты метеонаблюдений.
Построение карты
# Цветовая шкала для рельефа
dem_colors = colorRampPalette(c("darkolivegreen4", "lightyellow", "orange", "firebrick"))
# Шкала высот для рельефа
dem_levels = c(0, 50, 100, 200, 500, 1000, 1500,
2000, 2500, 3000, 3500, 4000, 5000)
dem_ncolors = length(dem_levels) - 1
dem_contours = st_contour(dem, breaks = dem_levels, contour_lines = TRUE)
old = theme_set(theme_bw())
# Смотрим как выглядит результат
ggplot() +
geom_stars(data = cut(dem, breaks = dem_levels)) +
coord_sf(crs = st_crs(dem)) +
scale_fill_manual(name = 'м',
values = dem_colors(dem_ncolors),
labels = dem_levels,
na.translate = FALSE,
guide = guide_legend(label.vjust = -0.3, reverse = TRUE)) +
geom_sf(data = dem_contours, color = 'black', size = 0.2) +
geom_sf(data = rivers, color = 'midnightblue', size = 0.2) +
geom_sf(data = lakes, color = 'midnightblue', fill = 'lightblue', size = 0.2) +
geom_sf(data = pts, color = 'black', size = 0.5) +
geom_sf(data = cities, shape = 21, fill = 'white') +
geom_text_repel(data = cities, mapping = aes(x = X, y = Y, label = name), box.padding = 0.2)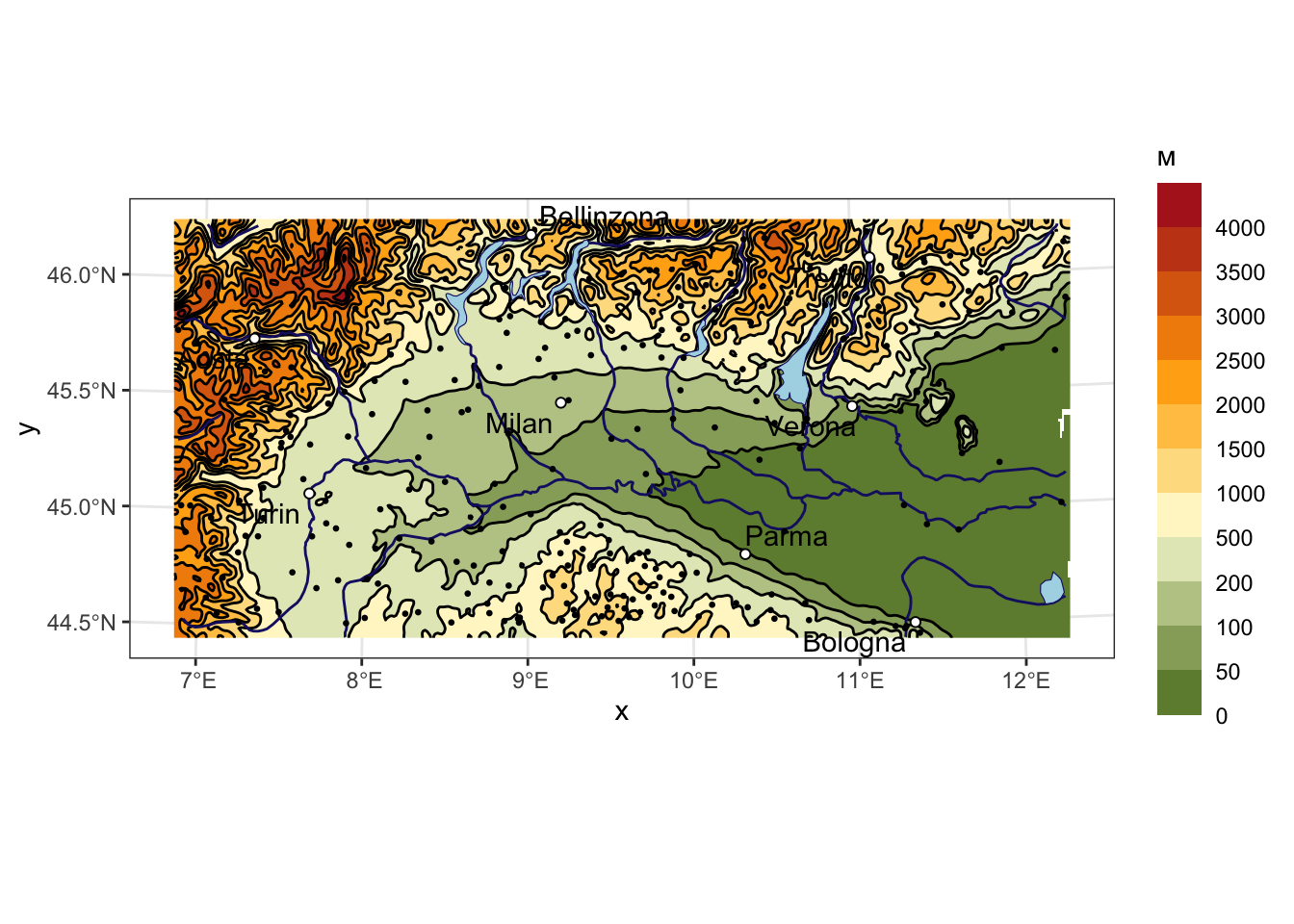
15.2 Построение сетки
Любопытным свойством пакетов R, отвечающих за интерполяцию данных, является их индифферентность относительно того, в каких точках эта интерполяция будет производиться. Это может быть как регулярная растровая сетка, так и множество точек в совершенно произвольных конфигурациях. Подобная гибкость делает процесс интерполяции данных чуть более сложным, чем в ГИС-пакетах, однако способствует полному и глубокому пониманию происходящего. Вы своими руками задаете пункты, в которых следует интерполировать значения.
Для построения сетки воспользуемся функцией st_as_stars() из пакета stars, передав ей ограничивающий прямоугольник исходного множества точек и разрешение сетки:
# ПОСТРОЕНИЕ СЕТКИ ДЛЯ ИНТЕРПОЛЯЦИИ
# получим ограничивающий прямоугольник вокруг точек:
box = st_bbox(pts)
envelope = box[c(1,3,2,4)]
px_grid = st_as_stars(box, dx = 10000, dy = 10000)
ggplot() +
geom_sf(data = pts, color = 'red') +
geom_sf(data = st_as_sf(px_grid), size = 0.5, fill = NA)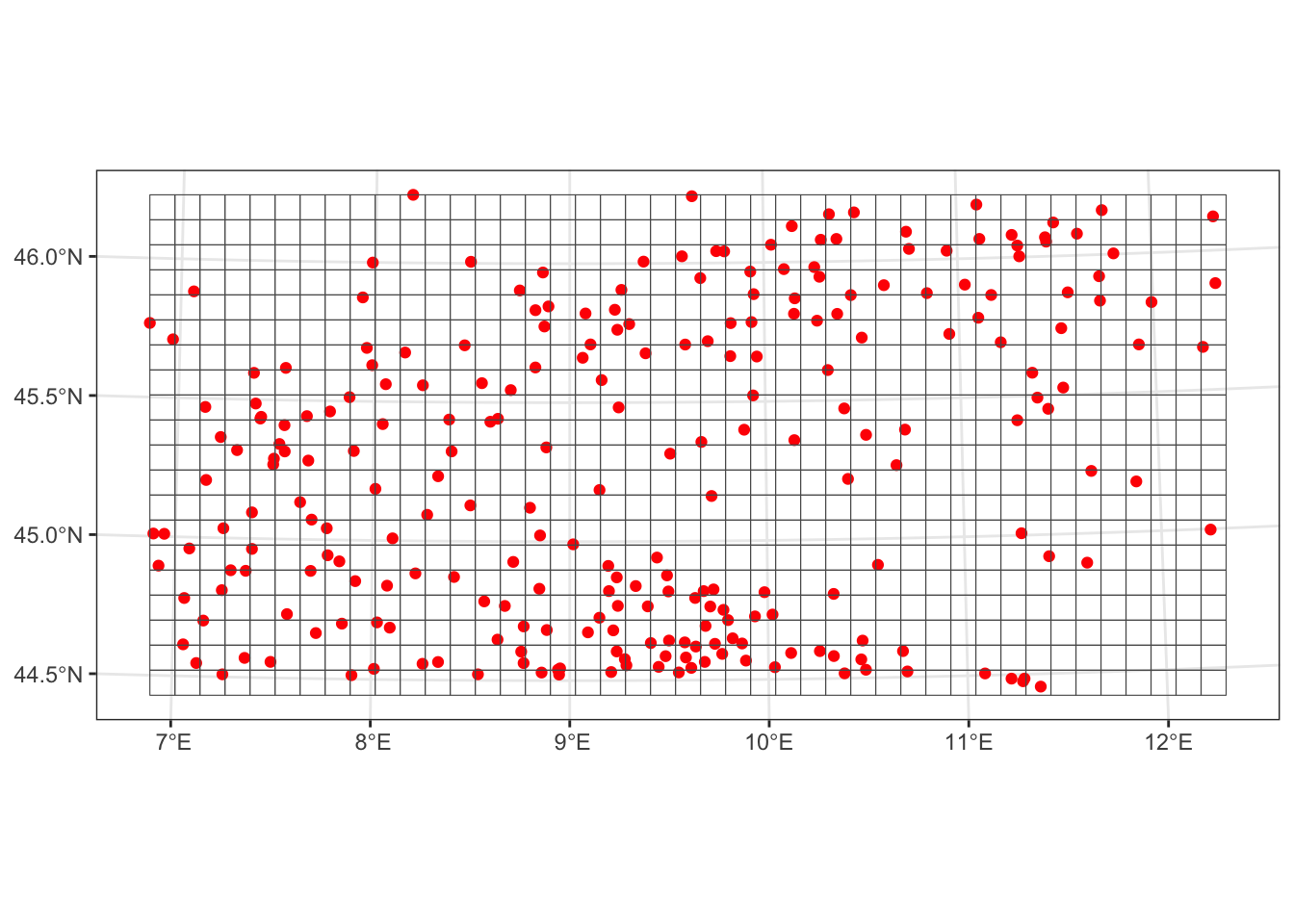
Получившееся представление можно назвать сеточной моделью. В пределах каждой ячейки величина будет считаться постоянной. Ее значение будет интерполировано в центре пиксела. Можно видеть, что интерполяционная сетка слегка выходит за пределы исходного охвата множества точек. Это связано с тем, что размеры прямоугольника, ограничивающего множество точек, не кратны выбранному разрешению растра (\(10 000\) м). Проблема, однако, не столько критична, если вы выбираете достаточно подробное (малое) разрешение растра, что мы и сделаем. Зададим его равным \(1 000\) м:
# создадим детальную растровую сетку
px_grid = st_as_stars(box, dx = 1000, dy = 1000)
# извлечем координаты точек в соответствующие столбцы, они нам пригодятся:
coords_grid = st_coordinates(px_grid)15.3 Интерполяционные методы
# Цветовая шкала для осадков
rain_colors = colorRampPalette(c("white", "dodgerblue", "dodgerblue4"))
# Шкала количества осадков и соответствющее число цветов
rain_levels = seq(0, 80, by=10)
rain_ncolors = length(rain_levels)-1
rain_legend = scale_fill_manual(name = 'мм',
values = rain_colors(rain_ncolors),
guide = guide_legend(label.vjust = -0.3, reverse = TRUE, title.position = "bottom"),
labels = rain_levels,
na.value = 'white',
drop = FALSE)
rain_mapping = aes(fill = cut(rain_24, breaks = rain_levels))15.3.1 Метод ближайшего соседа (nearest neighbour)
Данный метод является простейшим по сути подходом к интерполяции. В его основе лежит построение диаграммы Вороного исходного множества точек. Считается, что в пределах каждой ячейки диаграммы значение показателя постоянно и равно значению в центре ячейки. Далее поверх диаграммы накладывается сетка интерполируемых точек и снимаются соответствующие значения:
# МЕТОД БЛИЖАЙШЕГО СОСЕДА (NEAREST NEIGHBOR)
# Диаграмма Вороного
voronoi_sf = voronoi(coords, envelope) |>
st_as_sf() |>
st_set_crs(st_crs(pts)) |>
st_join(pts)
# Триангуляция Делоне
edges = pts |>
st_union() |>
st_triangulate()
# Визуализация
ggplot() +
geom_sf(data = voronoi_sf,
mapping = rain_mapping,
size = 0.2) +
rain_legend +
geom_sf(data = pts, color = 'red', size = 0.5) +
geom_sf(data = edges, color = 'red', size = 0.1, fill = NA)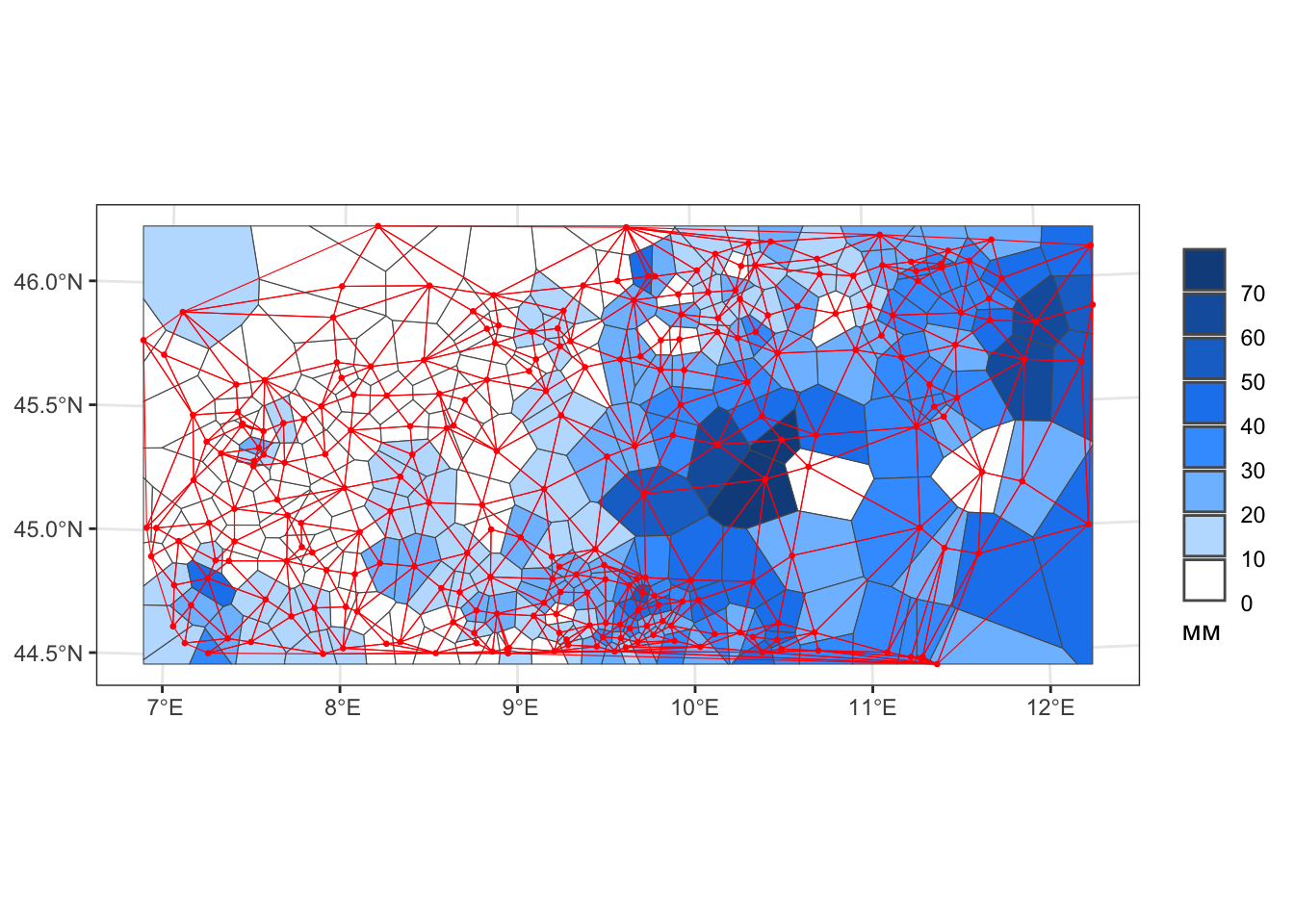
Если есть задача конвертировать это в растр, то надо сформировать новый растр и “перенести” на него информацию с полигонов:
# Создаем растр
rnn = st_rasterize(voronoi_sf["rain_24"], px_grid)
# Визуализируем:
ggplot() +
geom_stars(data = cut(rnn, breaks = rain_levels)) +
rain_legend +
coord_sf(crs = st_crs(pts))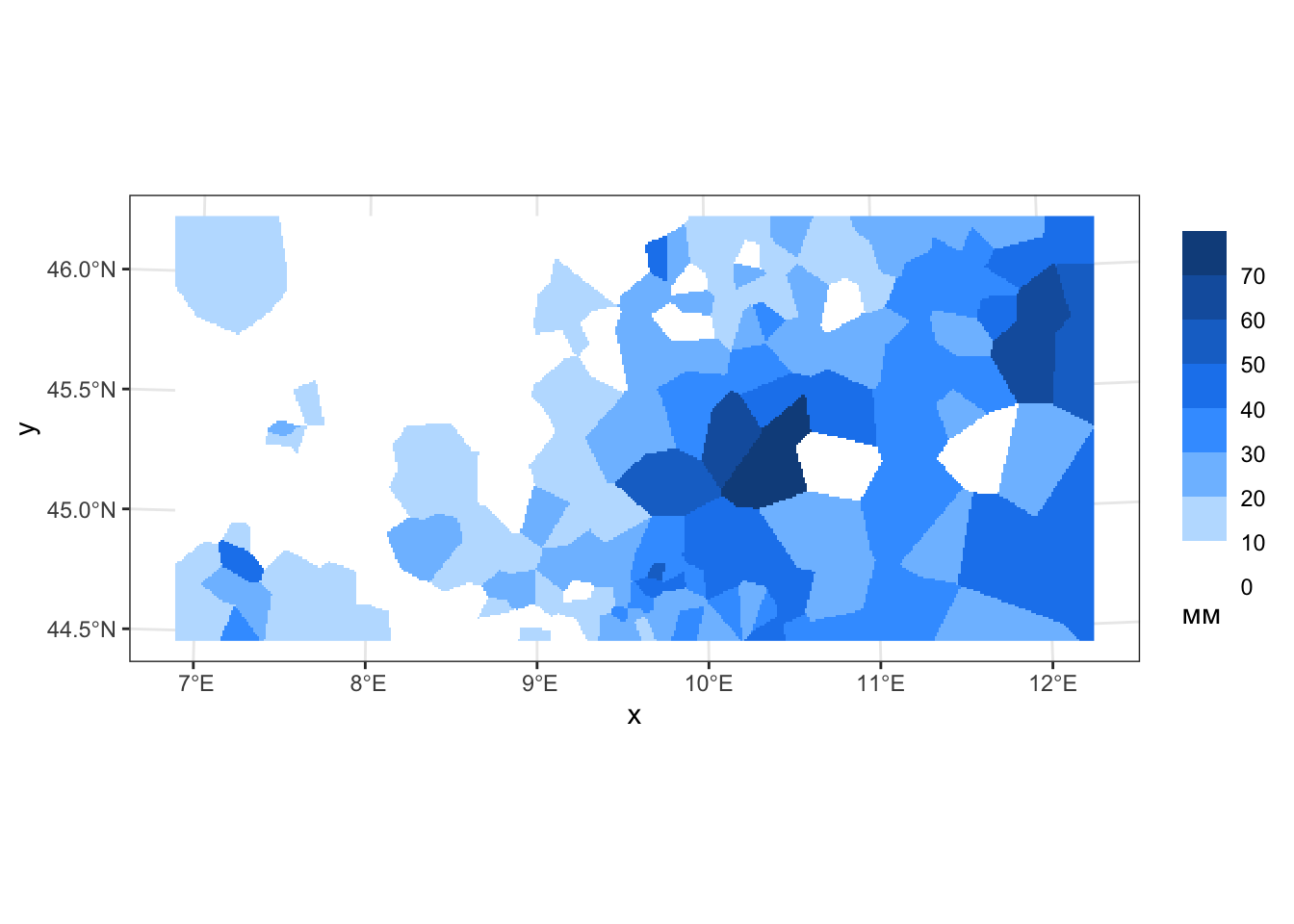
Видно, что полученная поверхность уже пиксельная. Для наглядности визуализируем ее в трехмерном виде. Для этого используем замечательный пакет plotly, предоставляющий интерфейс к одноименной библиотеке. Функция plot_ly(), отвечающая за построение графиков в этом пакете, требует для визуализации поверхности предоставить три компоненты:
x- вектор координат ячеек по оси \(Х\)y- вектор координат ячеек по оси \(Y\)z- матрицу значений, имеющую размеры \(length(x) \times length(y)\)
Поверхность будет раскрашиваться в различные цвета в зависимости от значений z, для управления цветами можно определить параметр colors, который должен иметь тип colorRamp:
rain_colors3d = colorRamp(c("white", "dodgerblue", "dodgerblue4"))
x = coords_grid[,'x'] %>% unique() # Получим координаты столбцов
y = coords_grid[,'y'] %>% unique() # Получим координаты строк
p = plot_ly(x = x,
y = y,
z = rnn$rain_24,
type = "surface",
colors = rain_colors3d)
layout(p, scene = list(aspectratio = list(x = 1, y = 1, z = 0.3)
))Понятное дело, что такая ступенчатая форма поверхности вряд ли соответствует реальному распределению показателя, который меняется в пространстве непрерывным образом. Можно сказать, что это первое приближение пространственного распределения.
15.3.2 Интерполяция на основе триангуляции
Интерполяция на основе триангуляции — метод интерполяции, результатом которого является уже не ступенчатая поверхность, а аппроксимированная треугольными гранями — наподобие того как объекты представлены в системах трехмерного моделирования и компьютерных играх. Триангуляция представляет собой поверхность, склеенную из треугольников, соединяющих исходные точки. Каждый треугольник является участком наклонной плоскости.
Границей триангуляции является выпуклая оболочка множества точек
Для выполнения интерполяции в произвольно заданной точке \((x, y)\) необходимо найти уравнение плоскости того треугольника который включает данную точку. В общем виде уравнение плоскости содержит четыре неизвестных коэффициента: \[ Ax + By + Cz + D = 0, \] Имея три точки \(p_1\), \(p_2\) и \(p_3\), искомые коэффициенты можно получить путем решения уравнения, левая часть которого задана в форме определителя: \[ \begin{vmatrix} x - x_1 & y - y_1 & z - z_1 \\ x_2 - x_1 & y_2 - y_1 & z_2 - z_1 \\ x_3 - x_1 & y_3 - y_1 & z_3 - z_1 \end{vmatrix} = 0 \] Коэффициенты \(A\), \(B\), \(C\) и \(D\) вычисляются заранее для каждого треугольника и хранятся вместе с триангуляцией. Получив коэффициенты нужного треугольника, искомую величину \(z(x, y)\) можно найти, выразив ее из вышеприведенного уравнения плоскости: \[ z(x, y) = -\frac{1}{C}(Ax+By+D) \]
Рассмотрим применение данного метода на практике.
# ИНТЕРПОЛЯЦИЯ НА ОСНОВЕ ТРИАНГУЛЯЦИИ (TRIANGULATION)
# Интерполируем. Параметр linear говорит о том, что показатель будет меняться вдоль ребер триангуляции линейно:
px_grid = px_grid |>
mutate(z_linear = interpp(x = coords[,1],
y = coords[,2],
z = pts$rain_24,
xo = coords_grid[,1],
yo = coords_grid[,2],
linear = TRUE)$z)
cont_linear = st_contour(px_grid['z_linear'], breaks = rain_levels, contour_lines = TRUE)
# Смотрим как выглядит результат
ggplot() +
geom_stars(data = cut(px_grid['z_linear'], breaks = rain_levels)) +
rain_legend +
coord_sf(crs = st_crs(pts)) +
geom_sf(data = cont_linear, color = 'black', size = 0.2) +
geom_sf(data = pts, color = 'red', size = 0.5) +
geom_sf(data = edges, color = 'red', size = 0.1, fill = NA)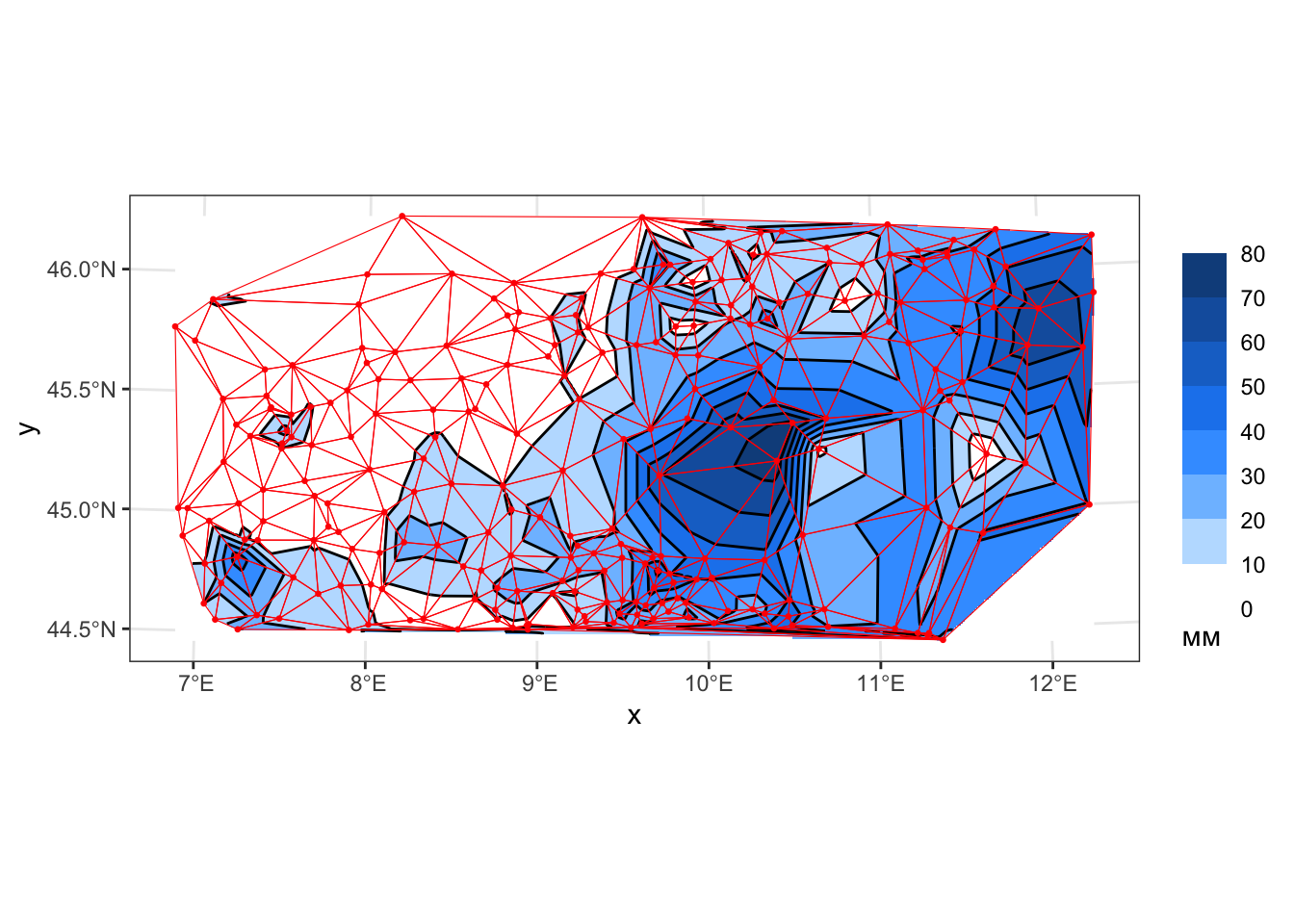
Обратите внимание, что все изломы (повороты) изолиний происходят на ребрах триангуляции, а внутри треугольников изолинии проходят параллельно друг другу. Каждый треугольник представляет собой фрагмент наклонной плоскости. Такой метод интерполяции, по сути, является самым простым и “честным” подходом, который близок к тому как горизонтали интерполируются вручную.
Рассмотрим поверхность в 3D:
p = plot_ly(x = x,
y = y,
z = px_grid$z_linear,
type = "surface",
colors = rain_colors3d)
layout(p, scene = list(aspectratio = list(x = 1, y = 1, z = 0.3)
))Линейная интерполяция на треугольниках, как можно видеть, выглядит достаточно угловато, хотя и существенно более правдоподобна, нежели ступенчатая поверхность, полученная методом ближайшего соседа.
Более гладкий результат можно получить, используя не линейный, а бикубический метод интерполяции на треугольниках, известный так же как метод Акимы (1978). Для того чтобы использовать его, необходимо в функции interpp указать параметр linear = FALSE. Помимо этого, параметр extrap = TRUE говорит о том, что можно производить экстраполяцию за пределами выпуклой оболочки точек (такая возможность недоступна в линейном случае):
px_grid = px_grid |>
mutate(z_spline = interpp(x = coords[,1],
y = coords[,2],
z = pts$rain_24,
xo = coords_grid[,1],
yo = coords_grid[,2],
linear = FALSE,
extrap = TRUE)$z)
cont_spline = st_contour(px_grid['z_spline'],
breaks = rain_levels,
contour_lines = TRUE)
# Смотрим как выглядит результат
ggplot() +
geom_stars(data = cut(px_grid['z_spline'], breaks = rain_levels)) +
rain_legend +
coord_sf(crs = st_crs(pts)) +
geom_sf(data = cont_spline, color = 'black', size = 0.2) +
geom_sf(data = pts, color = 'red', size = 0.5) +
geom_sf(data = edges, color = 'red', size = 0.1, fill = NA)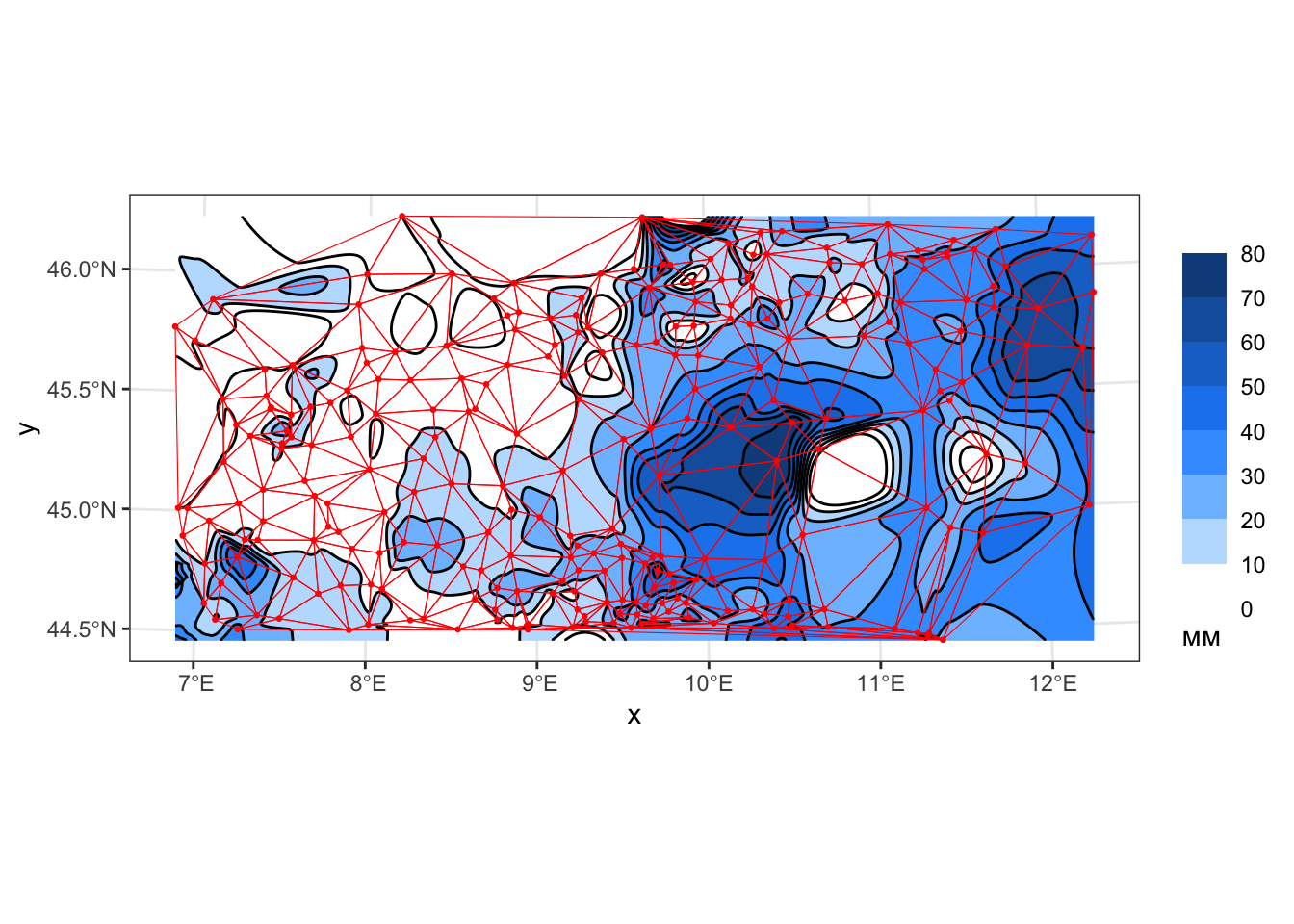
Полученные изолинии отличаются более плавным и естественным рисунком. Тем не менее, использование триангуляции все еще заметно по фестончатым изгибам изолиний на ребрах.
Смотрим наглядное представление поверхности в 3D:
p = plot_ly(x = x,
y = y,
z = px_grid$z_spline,
type = "surface",
colors = rain_colors3d)
layout(p, scene = list(aspectratio = list(x = 1, y = 1, z = 0.3)
))Можно видеть, что в данном случае получена уже гладкая поверхность, плотно натянутая на ребра триангуляции.
15.3.3 Метод обратно взвешенных расстояний (IDW)
В методе обратно взвешенных расстояний значение показателя в произвольной точке получается как средневзвешенная сумма значений в исходных точках. Веса определяются обратно пропорционально расстоянию: чем дальше исходная точка удалена, тем меньший вес она будет иметь в оценке. Формально значение функции в точке определяет согласно следующей формуле: \[ z(\mathbf{p}) = \begin{cases} \dfrac{\sum_{i = 1}^{N}{ w_i(\mathbf{p}) z_i } }{ \sum_{i = 1}^{N}{ w_i(\mathbf{p}) } }, & \text{если } d(\mathbf{p},\mathbf{p}_i) \neq 0 \text{ для всех } i, \\ z_i, & \text{если } d(\mathbf{p},\mathbf{p}_i) = 0 \text{ хотя бы для одного } i, \end{cases} \] где \(w_i(\mathbf{p}) = | \mathbf p - \mathbf p_i | ^{-\rho}\) — весовая функция.
Метод Шепарда — одна из наиболее распространенных модиификаций метода IDW. Веса вычисляются по формуле:
\[w_i(\mathbf{p}) = d^{-2}_i / \sum_{j=1}^n d^{-2}_j\]
Метод реализуется в R с помощью функции idw() из пакета gstat. Основным параметром метода является степень idp =, которая указывает, насколько быстро в зависимости от расстояния будет убывать вес исходной точки. По умолчанию idp = 2. При больших значениях степени (3, 4, 5, …) поверхность становится более платообразной, при меньших — островершинной.
Функция idw() принимает 4 параметра:
- Формула, указывающая название зависимой переменной и независимых переменных.
- Исходные точки.
- Результирующие точки.
- Степень весовой функции
idp.
Формулы полезны в тех случаях, когда известно (или делается предположение), что исследуемый показатель функционально связан с другой величиной. В этом случае запись Z ~ x означает, что сначала будет построена линейная регрессия \(Z(x)\) и на основе нее получена грубая оценка показателя в каждой результирующей точке. Интерполяции же будут подвергаться случайные остатки между исходными величинами в точках и теми, что получены по регрессии. Эти остатки добавляются в результирующих точках к оценке, полученной по регрессии.
Пока что мы воспользуемся стандартной записью вида Z ~ 1, которая означает, что интерполироваться будет непосредственно исходная величина. В качестве Z надо указать название столбца, содержащего значения показателя. Этот столбец должен находиться в слое с исходными точками, который передается в параметр locations =. Сетка новых точек передается в параметр newdata.
Рассмотрим, как меняется вид поверхности при разных значениях idp.
# МЕТОД ОБРАТНО ВЗЕШЕННЫХ РАССТОЯНИЙ (IDW --- INVERSE DISTANCE WEIGHTED)
# Интерполируем количество осадков:
px_grid = px_grid |>
mutate(z_idw2 = gstat::idw(rain_24 ~ 1, locations = pts, newdata = px_grid, idp = 2.0) |> pull(var1.pred) |> as('vector'),
z_idw3 = gstat::idw(rain_24 ~ 1, locations = pts, newdata = px_grid, idp = 3.0) |> pull(var1.pred) |> as('vector'),
z_idw4 = gstat::idw(rain_24 ~ 1, locations = pts, newdata = px_grid, idp = 4.0) |> pull(var1.pred) |> as('vector'),
z_idw5 = gstat::idw(rain_24 ~ 1, locations = pts, newdata = px_grid, idp = 5.0) |> pull(var1.pred) |> as('vector'))
cont_idw2 = st_contour(px_grid['z_idw2'],
breaks = rain_levels,
contour_lines = TRUE)
cont_idw3 = st_contour(px_grid['z_idw3'],
breaks = rain_levels,
contour_lines = TRUE)
cont_idw4 = st_contour(px_grid['z_idw4'],
breaks = rain_levels,
contour_lines = TRUE)
cont_idw5 = st_contour(px_grid['z_idw5'],
breaks = rain_levels,
contour_lines = TRUE)
ggplot() +
geom_stars(data = cut(px_grid['z_idw2'], breaks = rain_levels)) +
rain_legend +
coord_sf(crs = st_crs(pts)) +
geom_sf(data = cont_idw2, color = 'black', size = 0.2) +
geom_sf(data = pts, color = 'red', size = 0.5)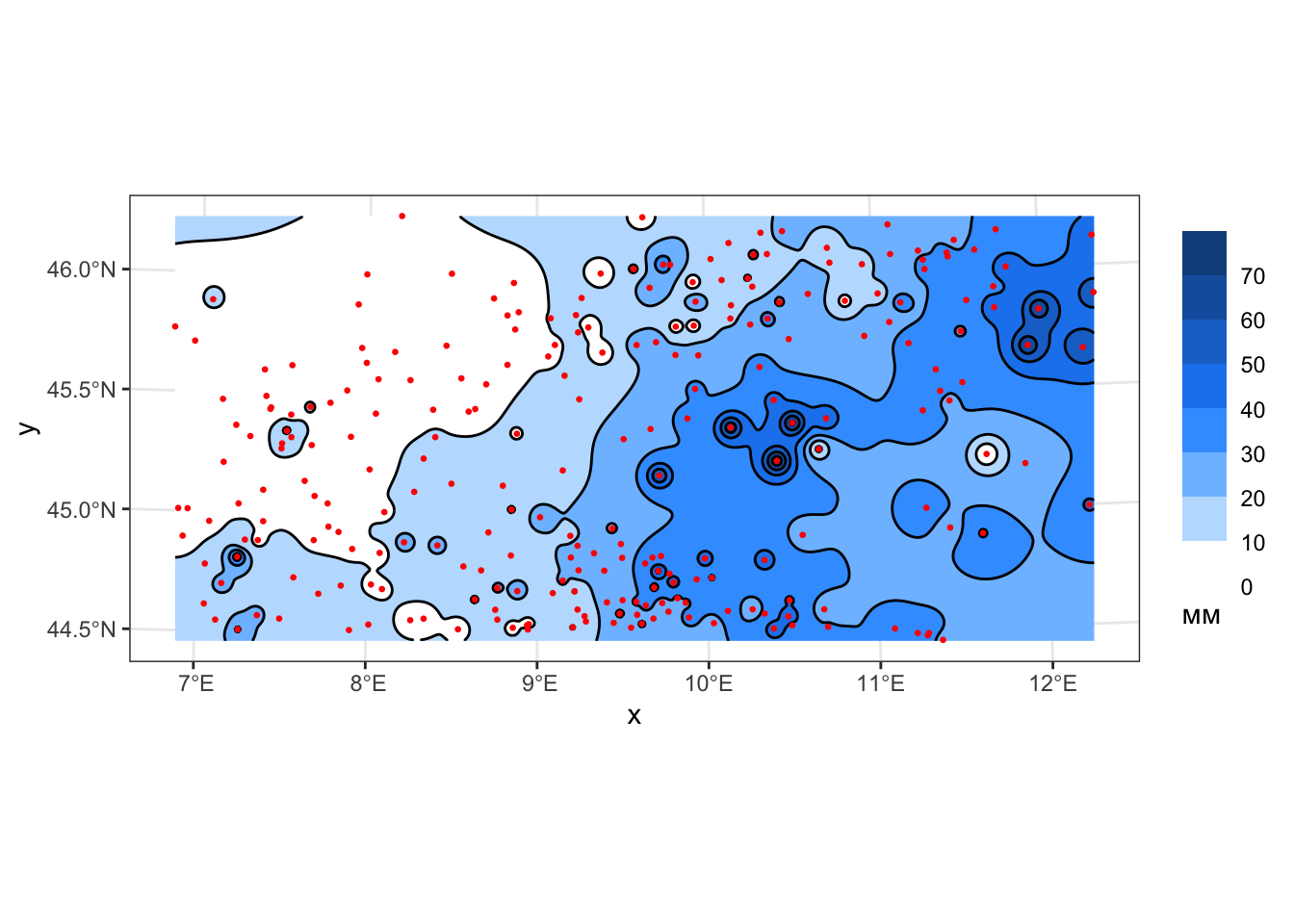
ggplot() +
geom_stars(data = cut(px_grid['z_idw3'], breaks = rain_levels)) +
rain_legend +
coord_sf(crs = st_crs(pts)) +
geom_sf(data = cont_idw3, color = 'black', size = 0.2) +
geom_sf(data = pts, color = 'red', size = 0.5)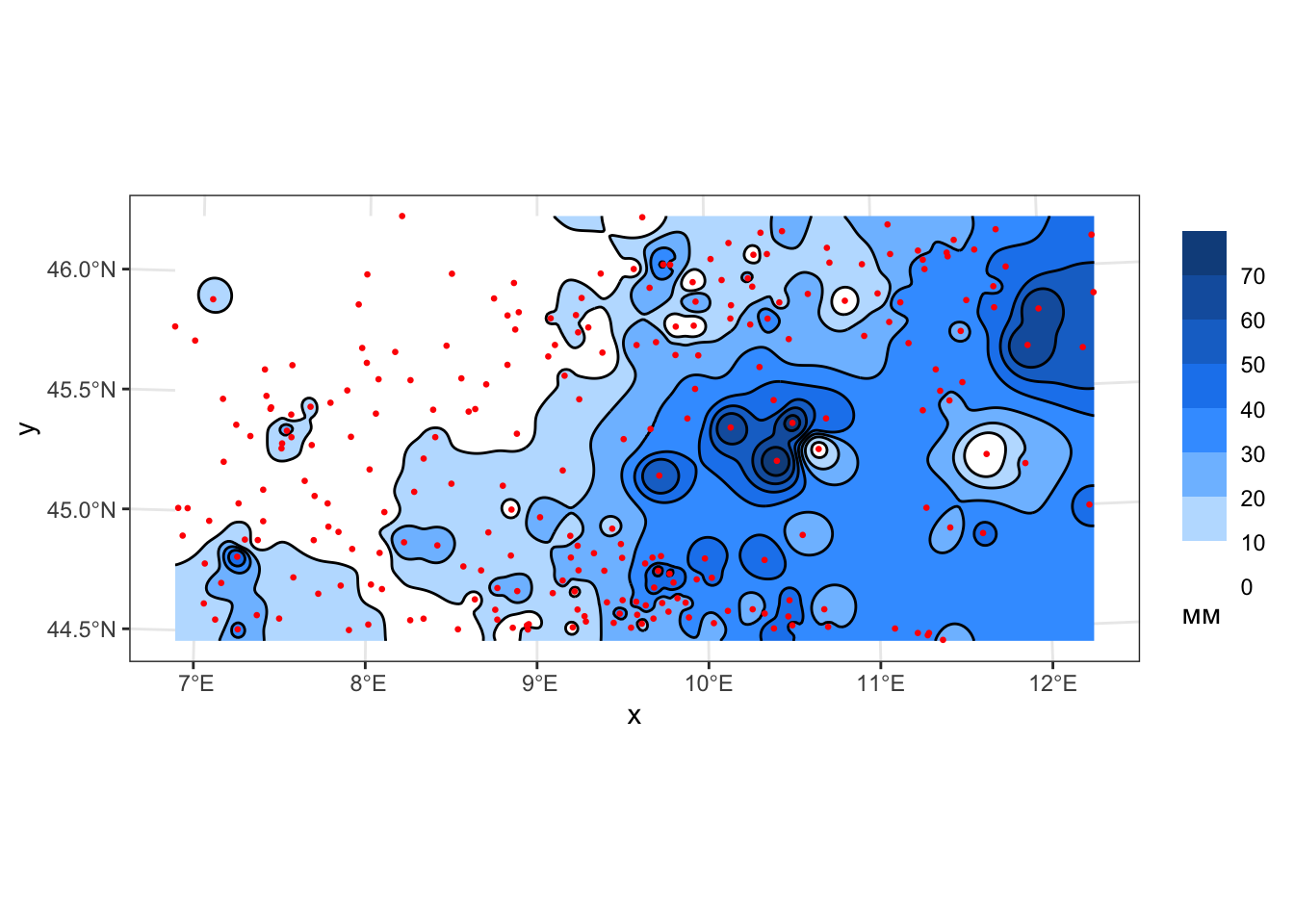
ggplot() +
geom_stars(data = cut(px_grid['z_idw4'], breaks = rain_levels)) +
rain_legend +
coord_sf(crs = st_crs(pts)) +
geom_sf(data = cont_idw4, color = 'black', size = 0.2) +
geom_sf(data = pts, color = 'red', size = 0.5)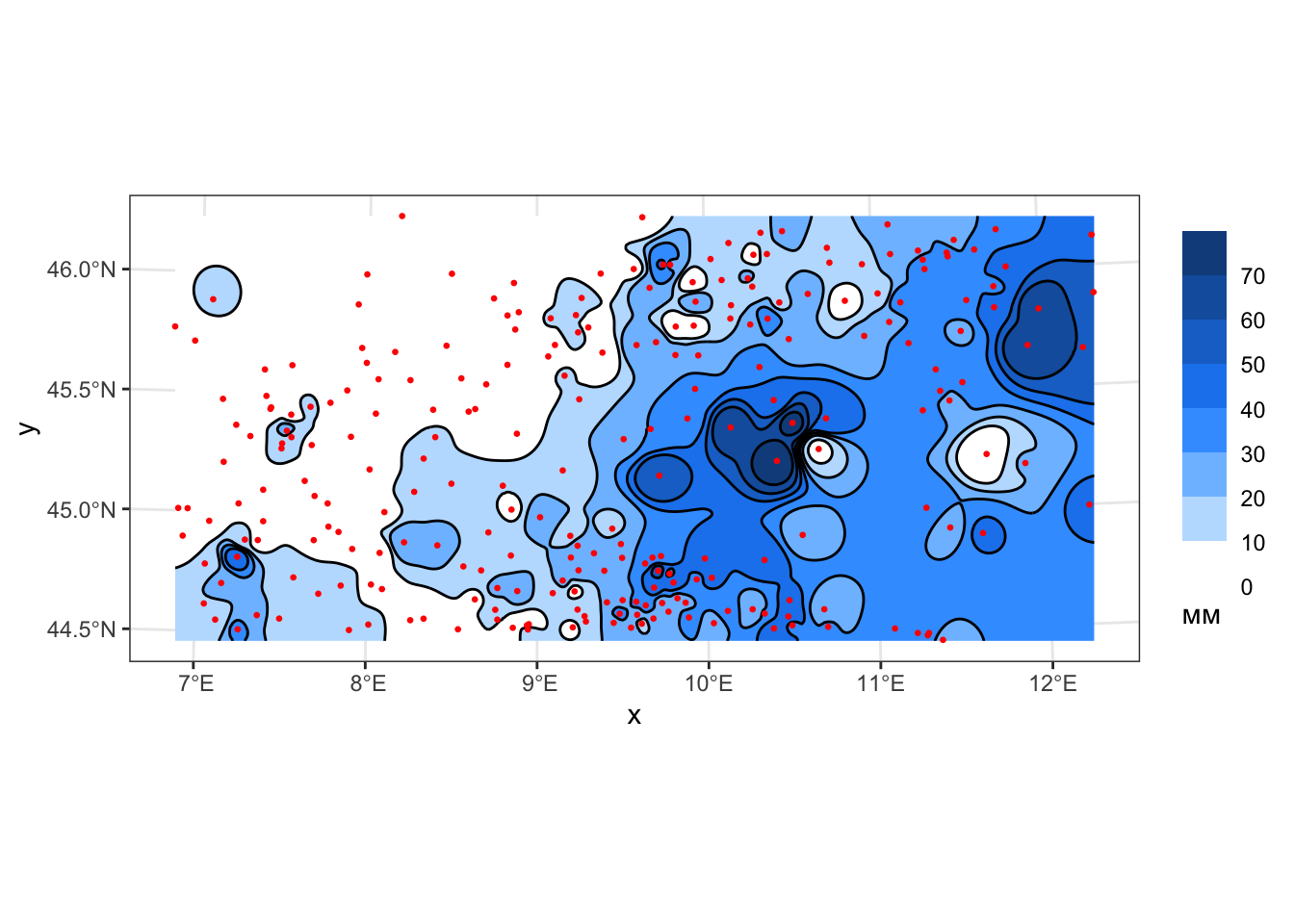
ggplot() +
geom_stars(data = cut(px_grid['z_idw5'], breaks = rain_levels)) +
rain_legend +
coord_sf(crs = st_crs(pts)) +
geom_sf(data = cont_idw5, color = 'black', size = 0.2) +
geom_sf(data = pts, color = 'red', size = 0.5)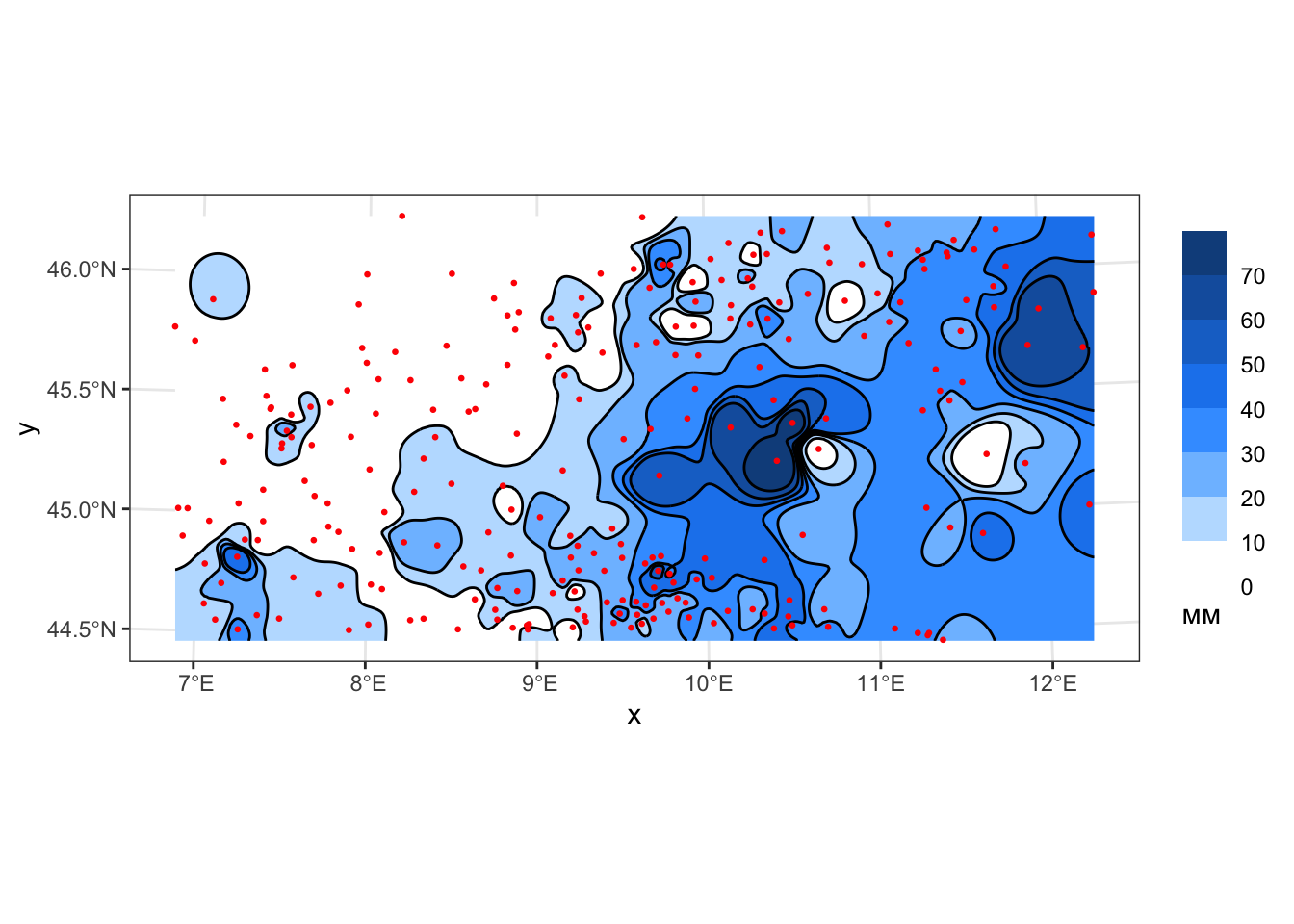
Поскольку производная функции ОВР в каждой точке исходных данных равняется нулю (это следует из определения функции), данный метод формирует хорошо заметные замкнутые изолинии, оконтуривающие точки исходных данных. Данный эффект носит название эффекта “бычьих глаз” и относится наиболее критикуемым недостаткам метода ОВР. При увеличении степени весовой функции, однако, происходит размывание данного эффекта, выраженные в изолиниях вершины и впадины приобретают платообразный характер.
Наглядное представление о характере поверхности, получаемой методом ОВР, дает трехмерная визуализация:
p = plot_ly(x = x,
y = y,
z = px_grid$z_idw3,
type = "surface",
colors = rain_colors3d)
layout(p, scene = list(aspectratio =
list(x = 1, y = 1, z = 0.3)
))Любопытным фактом является то, что при стремлении параметра idp к плюс-бесконечности получаемая поверхность становится все более похожей не результат интерполяции методом ближайшего соседа. А именно этот метод, как мы помним, дает ступенчатую платообразную поверхность. Данный эффект легко проверить на практике, задав достаточно большой параметр idp, например \(30\):
px_grid = px_grid |>
mutate(z_idw30 =
gstat::idw(
rain_24 ~ 1,
locations = pts,
newdata = px_grid,
idp = 30.0
) |> pull(var1.pred) |> as('vector')
)
## [inverse distance weighted interpolation]
cont_idw30 = st_contour(px_grid['z_idw30'],
breaks = rain_levels,
contour_lines = TRUE)
ggplot() +
geom_stars(data = cut(px_grid['z_idw30'], breaks = rain_levels)) +
rain_legend +
coord_sf(crs = st_crs(pts)) +
geom_sf(data = cont_idw30, color = 'black', size = 0.2) +
geom_sf(data = pts, color = 'red', size = 0.5) +
geom_sf(data = voronoi_sf, color = 'violet', fill = NA, size = 0.2)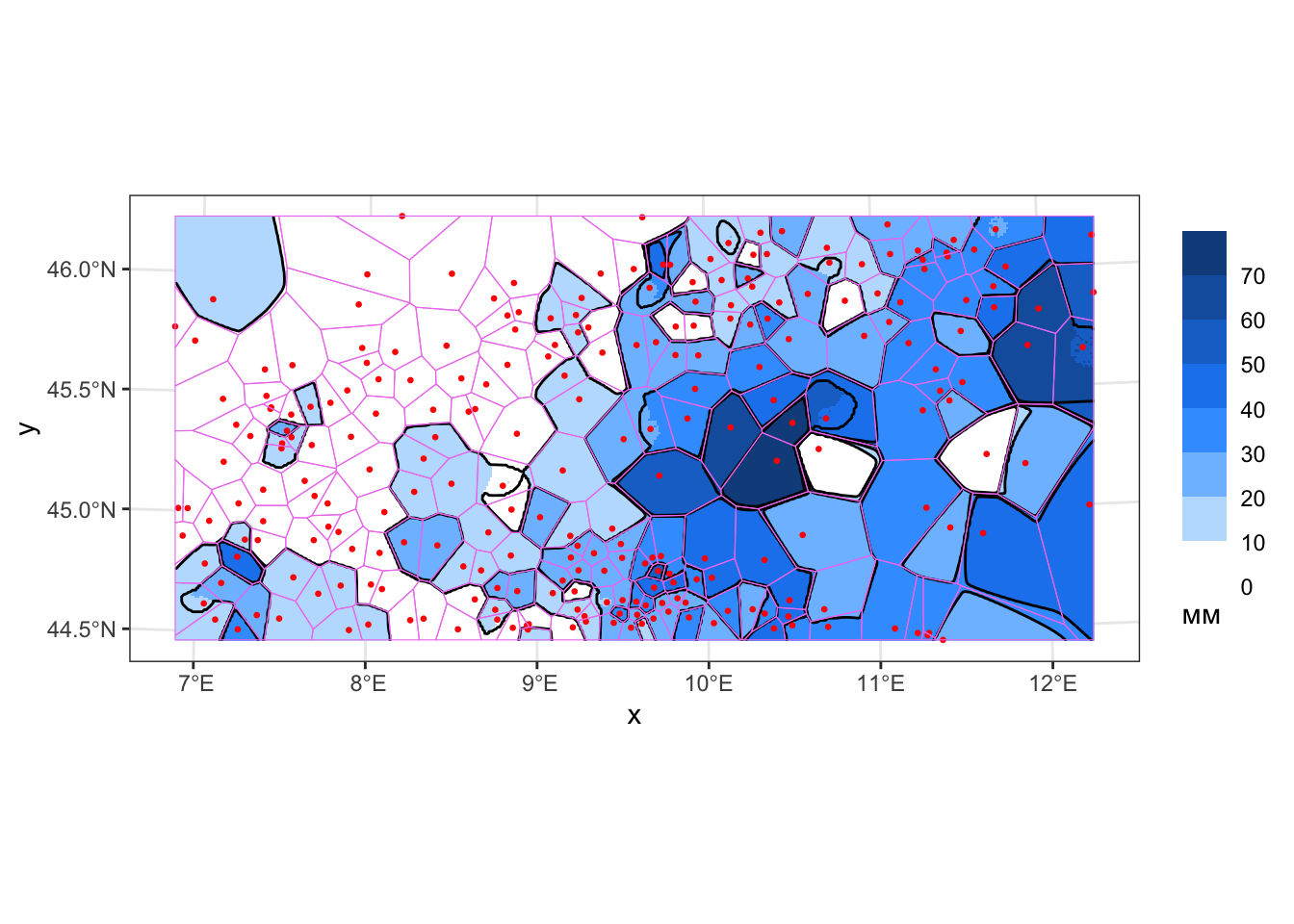
Рассмотрим полученную поверхность в 3D:
p = plot_ly(x = x,
y = y,
z = px_grid$z_idw30,
type = "surface",
colors = rain_colors3d)
layout(p, scene = list(aspectratio = list(x = 1, y = 1, z = 0.3)
))15.3.4 Метод радиальных базисных функций (РБФ)
В методе радиальных базисных функций значение в точке \(p\) находится путем взвешенного осреднения радиальных функций \(\phi\):
\[Z(\textbf{p}) = \sum_{i=1}^n \lambda_i \phi\big(\lVert \textbf{p} - \textbf{p}_i\rVert\big)\] где коэффициенты \(\lambda_i\) находятся заранее перед интерполяцией исходя из \(n\) условий вида \(Z(\textbf{p}_i) = z_i\).
К числу широко используемых радиальных функций относятся:
Мультиквадрики: \(\phi(r) = \sqrt{r^2 + \delta^2}\)
Обратные мультиквадрики: \(\phi(r) = 1 / \sqrt{r^2 + \delta^2}\)
Мульти-логарифмическая: \(\phi(r) = \ln(r^2 + \delta^2)\)
Сплайны минимальной кривизны: \(\phi(r) = r^2 \ln(r^2)\)
Метод РБФ является одним из самых гибких благодаря широким возможностям выбора радиальной функции. Недостатком же его является то, что поверхность может выходить за пределы исходного диапазона значений (хотя и обязательно проходит через исходные точки).
Особого внимания среди радиальных функций заслуживают сплайны - функции, выполняющие некоторое дополнительное условие (условия) при одновременном выполнении условий интерполяции (прохождение через исходные точки). В частности, приведенный выше сплайн минимальной кривизны (thin plate spline — TPS) дает поверхность, обладающую максимально низкой кривизной между исходными точками. В такой поверхности будут отсутствовать резкие скачки и понижения, что мы видели на поверхности, построенной методом ОВР.
На языке R сплайны минимальной кривизны реализованы в пакете fields. Сначала необходимо инициализировать процесс интерполяции с помощью функции Tps(), передав ей координаты исходных точек и значения показателя в них. Дополнительно при необходимости указывается параметр scale.type = 'unscaled', который означает, что не следует масштабировать координаты исходных точек так чтобы область определения стала квадратной:
# РАДИАЛЬНЫЕ БАЗИСНЫЕ ФУНКЦИИ (RADIAL BASIS FUNCTIONS)
pred = Tps(coords, pts$rain_24, scale.type = 'unscaled')
# После этого можно интерполировать значения с помощью функции predict():
px_grid = px_grid |>
mutate(z_tps = predict(pred, coords_grid))
# Придется расширить шкалу, так как сплайновая поверхность выходит за пределы исходных значений:
tps_breaks = seq(-10,90,by=10)
tps_ncolors = length(tps_breaks) - 1
cont_tps = st_contour(px_grid['z_tps'],
breaks = tps_breaks,
contour_lines = TRUE)
# Виузализируем результат:
ggplot() +
geom_stars(data = cut(px_grid['z_tps'], breaks = tps_breaks)) +
scale_fill_manual(name = 'мм',
values = rain_colors(tps_ncolors),
labels = paste(tps_breaks[-tps_ncolors-1], '-', tps_breaks[-1])) +
coord_sf(crs = st_crs(pts)) +
geom_sf(data = cont_tps, color = 'black', size = 0.2) +
geom_sf(data = pts, color = 'red', size = 0.5)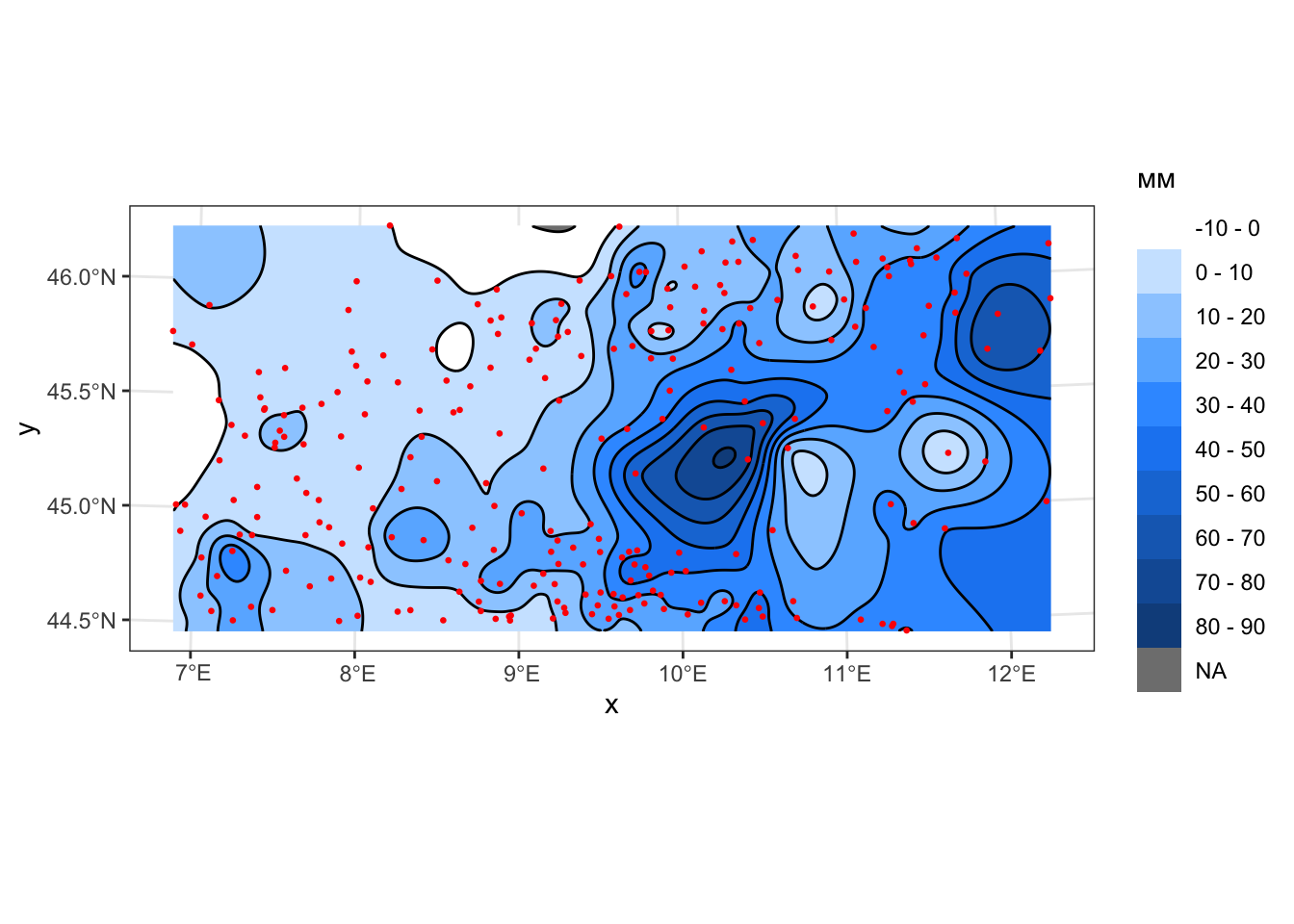
Можно видеть, что по плавному характеру изолиний и отсутствию артефактов в виде “бычьих глаз” интерполяция методом РБФ существенно ближе к ожидаемому распределению показателя, а также удачно сглаживает неравномерность распределения исходных данных.
Смотрим, как выглядит поверхность в 3D:
p = plot_ly(x = x,
y = y,
z = px_grid$z_tps,
type = "surface",
colors = rain_colors3d)
layout(p, scene = list(aspectratio =
list(x = 1, y = 1, z = 0.3)
))15.3.5 Метод иерархических базисных сплайнов (B-сплайнов)
В методе иерархических базисных сплайнов интерполяция прооизводится итеративно на нескольких уровнях детализации сетки: от более грубых к детальным. Пусть сетка \(\Phi\) состоит из узлов \(\phi_{ij}\). Тогда функция аппроксимации в узле \(\phi_{ij}\) определяется следующим образом:
\[f(x, y) = \sum_{k=0}^3 \sum_{l=0}^3 B_k(s)B_l(t) \phi_{i+k, j+l},\] где \(i = \lfloor x \rfloor -1\), \(j = \lfloor y \rfloor -1\), \(s = x - \lfloor x \rfloor\) и \(t = y - \lfloor y \rfloor\).
Функции \(B_k\) и \(B_l\) представляют собой кубические базисные функции в форме B-сплайнов, определяемые как:
\[B_0(t) = (1-t)^3/6,\\ B_1(t) = (3t^3 - 6t^2 + 4)/6,\\ B_2(t) = (-3t^3 + 3t^2 + 3t + 1)/6,\\ B_3(t) = t^3/6,\]
где \(0 \leq t < 1\). Данные функции служат в качестве весовых коэффициентов соответствующих узлов при определении значения в точке \((x, y)\).
Интерполируемые значения \(\phi_{ij}\) находятся исходя из условия минимального отклонения функции \(f(x, y)\) от значений точек исходных данных. В методе иерархических базисных сплайнов используется иерархия сеток \(\Phi_0, \Phi_1, ..., \Phi_h\), наложенных на область \(\Omega\). На каждом последующем уровне вложенности, разрешение сетки удваивается, а интерполяции подвергаются остатки между исходными и интерполированными значениями в точках, полученные на предыдущем этапе. Финальные значения в узлах сетки определяются суммой функций по всем уровням иерархии:
\[f = \sum_{k=0}^h f_k\]Таким образом, достигается последовательная (инкрементная) аппроксимация исходной функции, которая выполняется быстрее для областей с разреженными данными (интерполяция достигается уже на первых итерациях) и требует большего количества итераций для участков с плотно расположенными данными.
К достоинствам метода ИБС можно отнести:
- Поверхность получается сразу для всех узлов, нет необходимости решать систему линейных уравнений для каждого узла сетки;
- Метод является локальным: исходные точки, удаленные от текущего узла ЦМР далее чем на 2 узла, не оказывают на нее влияние. В результате этого метод ИБС получается чрезвычайно быстрым и эффективным в вычислительном плане.
- Мультимасштабность метода позволяет эффективно использовать его при интерполяции данных, распределенных кластерным образом — например, данных профилирования.
Метод иерархических базисных сплайнов доступен в пакете MBA. Чтобы использовать его, сначала необходимо подготовить исходные данные. Они должны представлять из себя матрицу из трех столбцов: X, Y, Показатель:
# ИЕРАРХИЧЕСКИЕ БАЗИСНЫЕ СПЛАЙНЫ (HIERARCHICAL BASIS SPLINES)
mba_data = cbind(coords, pts$rain_24)Метод ИБС, так же как и РБФ, предполагает по умолчанию, что область определения должна быть квадратной. Если разброс координат по осям X и Y не одинаков, поверхность будет искусственно растянута или сжата. Чтобы этого не произошло, необходимо сначала рассчитать пропорции ЦМР. Ранее мы уже создали объект envelope, который хранит крайние координаты по X и Y:
ratio = (envelope[2] - envelope[1])/(envelope[4] - envelope[3])
# После этих приготовлений можно осуществить интерполяцию
px_grid = px_grid |>
mutate(z_bspline =
mba.points(
mba_data, coords_grid,
n = 1, m = ratio
)$xyz.est[, 'z']
)
# Строим горизонтали
cont_bspline = st_contour(px_grid['z_bspline'],
breaks = tps_breaks,
contour_lines = TRUE)
# Виузализируем результат:
ggplot() +
geom_stars(data = cut(px_grid['z_bspline'], breaks = tps_breaks)) +
scale_fill_manual(name = 'мм',
values = rain_colors(tps_ncolors),
labels = paste(tps_breaks[-tps_ncolors-1], '-', tps_breaks[-1])) +
coord_sf(crs = st_crs(pts)) +
geom_sf(data = cont_bspline, color = 'black', size = 0.2) +
geom_sf(data = pts, color = 'red', size = 0.5)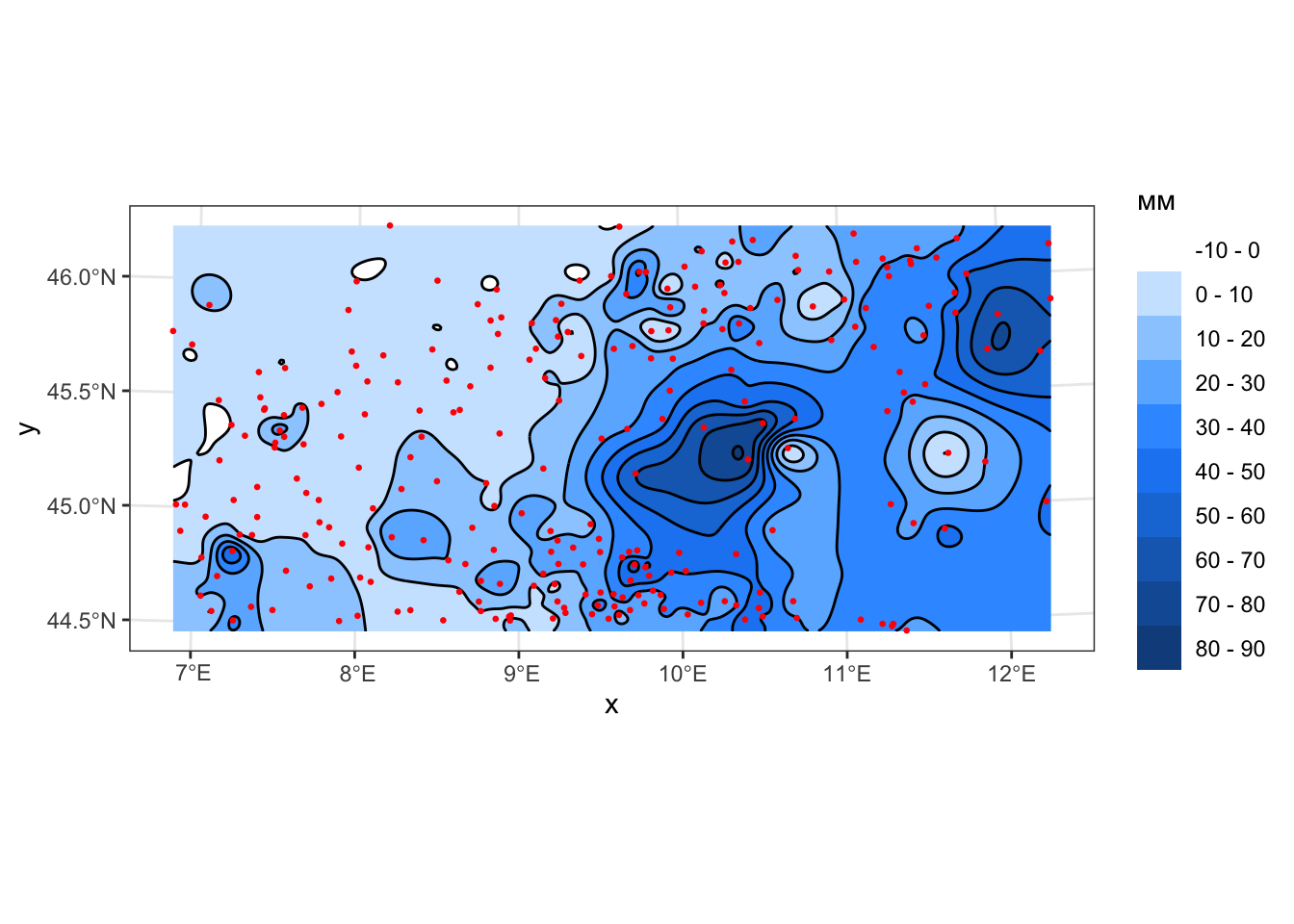
Можно видеть, что метод иерархических базисных сплайнов обеспечивает некий оптимум представления поверхности. С одной стороны, он, как и метод РБФ, дает гладкую и достаточно генерализованную поверхность. С другой стороны, на участках с плотным размещением исходных данных метод ИБС раскрывает локальные нюансы поверхности, чего лишен метод РБФ, и что более типично для метода ОВР.
Наконец, рассмотрим результат в трехмерном виде:
p = plot_ly(x = x,
y = y,
z = px_grid$z_bspline,
type = "surface",
colors = rain_colors3d)
layout(p, scene = list(aspectratio =
list(x = 1, y = 1, z = 0.3)
))Итак, в настоящем модуле мы рассмотрели несколько распространенных методов детерминистической интерполяции поверхностей по данным в нерегулярно расположенных точках. В следующем модуле мы рассмотрим методы аппроксимации, которые могут быть полезны для работы с данными, обладающими высоким уровнем шума, а также для оценки пространственных трендов изменения показателя.
15.4 Аппроксимационные методы
Аппроксимационные методы используются для выявления пространственных трендов - глобальных или локальных. В зависимости от этого они и классифицируются. Полученная поверхность в каждом узле показывает средневзвешенное (типичное) значение в заданной окрестности. Таким образом, задача аппроксимации — убрать детали и выявить основные закономерности пространственного распределения. При проведении аппроксимации условие прохождения поверхности через исходные точки не применяется. В случае глобального тренда окрестность аппроксимации включает весь набор исходных точек.
Локальные аппроксимации учитывают только ближайшие точки, причем общепринятым является подход, в котором окрестность определяется не расстоянием, а заданным количеством ближайших точек (или их долей от общего числа). В этом случае в области сгущения исходных данных локальная аппроксимация будет строиться по меньшей окрестности, что позволит отразить нюансы изменения показателя. И в локальных и в глобальных аппроксимациях используются обычно полиномиальные поверхности степени от \(0\) до \(3\). Коэффициенты полиномов подбираются методом наименьших квадратов для минимизации отклонения поверхности от исходных точек в заданной окрестности. В случае если степень равна \(0\), поверхность представляет из себя константу, или горизонтальную плоскость. Для степени \(1\) возможно построение наклонной плоскости. Степени \(2\) и \(3\) соответствуют квадратичным и кубическим поверхностям. Степени большего порядка для построения трендов, как правило, не используются.
15.4.1 Глобальный тренд
Построение поверхности глобального тренда можно осуществить с помощью геостатистического пакета gstat, с которым мы познакомимся в следующем модуле. Для этого необходимо сначала создать объект gstat, используя формулу (см. метод ОВР), исходные точки и степень аппроксимации. После этого аппроксимация осуществляется с помощью функции predict(). Дальнейшие действия совпадают со стандартным алгоритмом, который мы использовали ранее.
# ГЛОБАЛЬНАЯ АППРОКСИМАЦИЯ (GLOBAL APPROXIMATION)
# Создаем объект gstat и интерполируем на его основе. Столбец, указываемый в параметре formula, должен содержаться
# в наборе данных, который передается в параметр data:
px_grid = px_grid |>
mutate(z_trend1 = predict(gstat(formula = rain_24 ~ 1, data = pts, degree = 1),
newdata = px_grid) |> pull(var1.pred) |> as('vector'),
z_trend2 = predict(gstat(formula = rain_24 ~ 1, data = pts, degree = 2),
newdata = px_grid) |> pull(var1.pred) |> as('vector'),
z_trend3 = predict(gstat(formula = rain_24 ~ 1, data = pts, degree = 3),
newdata = px_grid) |> pull(var1.pred) |> as('vector'))
# Строим горизонтали
cont_trend1 = st_contour(px_grid['z_trend1'],
breaks = rain_levels,
contour_lines = TRUE)
cont_trend2 = st_contour(px_grid['z_trend2'],
breaks = rain_levels,
contour_lines = TRUE)
cont_trend3 = st_contour(px_grid['z_trend3'],
breaks = rain_levels,
contour_lines = TRUE)
ggplot() +
geom_stars(data = cut(px_grid['z_trend1'], breaks = rain_levels)) +
rain_legend +
coord_sf(crs = st_crs(pts)) +
geom_sf(data = cont_trend1, color = 'black', size = 0.2) +
geom_sf(data = pts, color = 'red', size = 0.5)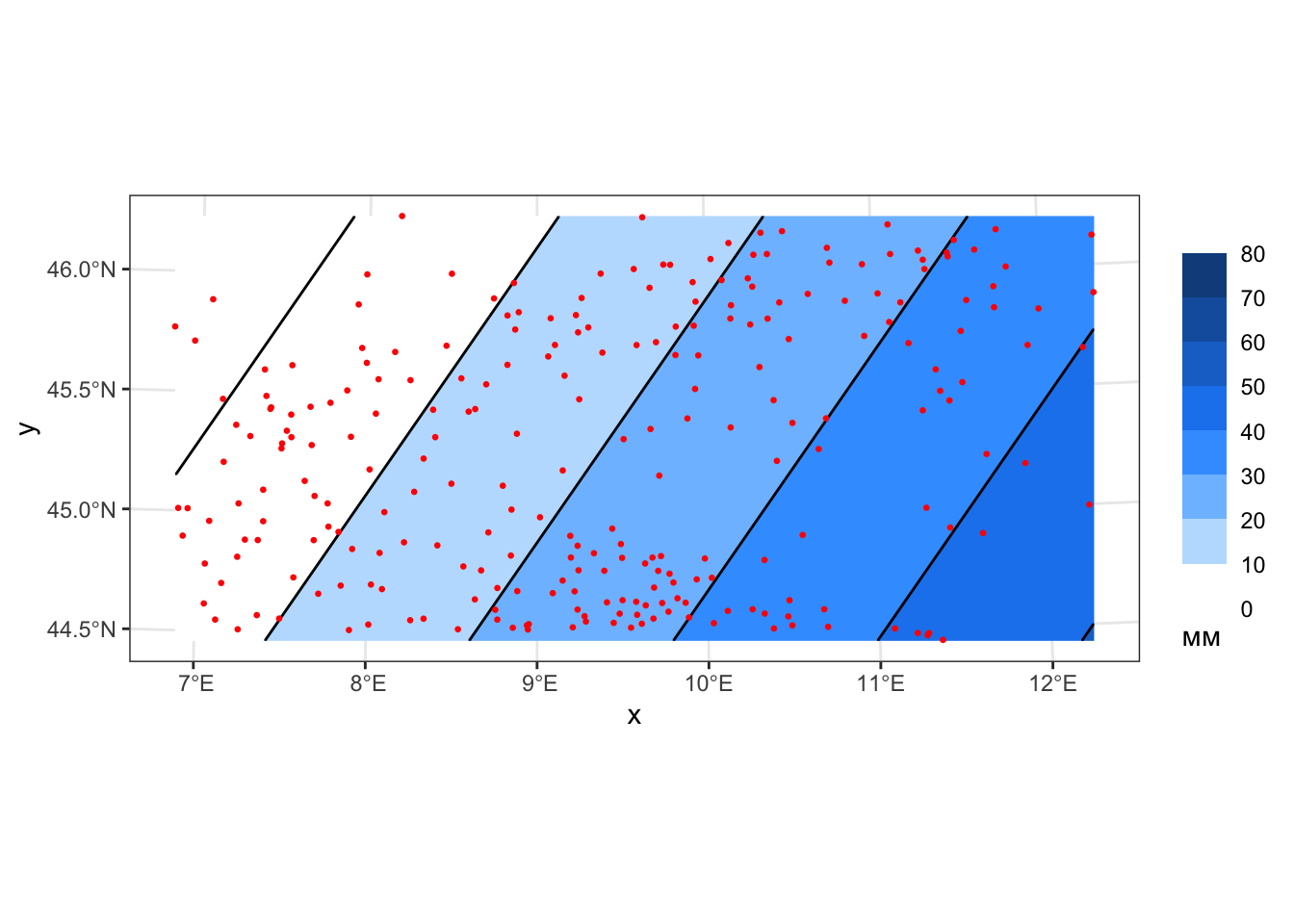
ggplot() +
geom_stars(data = cut(px_grid['z_trend2'], breaks = rain_levels)) +
rain_legend +
coord_sf(crs = st_crs(pts)) +
geom_sf(data = cont_trend2, color = 'black', size = 0.2) +
geom_sf(data = pts, color = 'red', size = 0.5)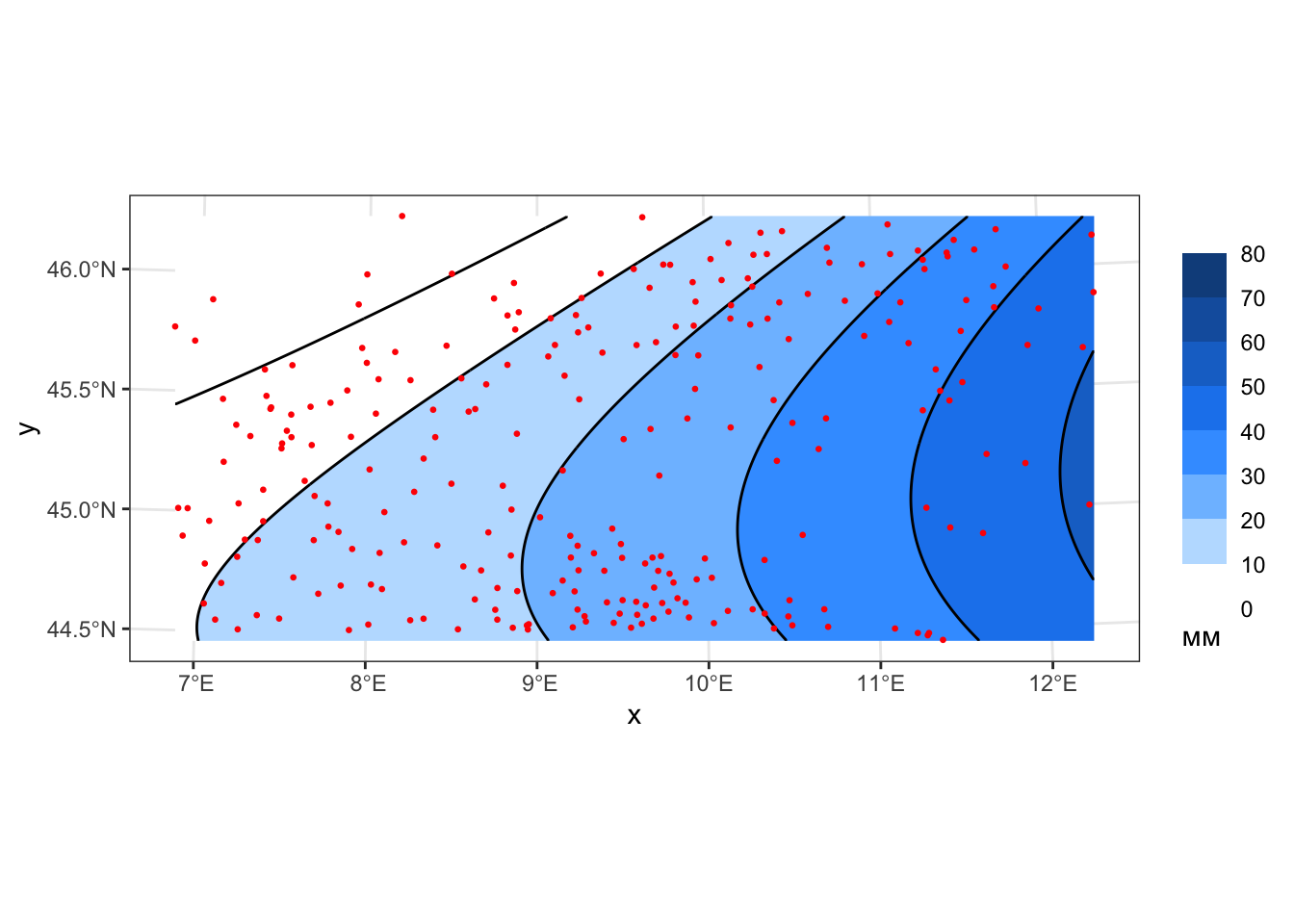
ggplot() +
geom_stars(data = cut(px_grid['z_trend3'], breaks = rain_levels)) +
rain_legend +
coord_sf(crs = st_crs(pts)) +
geom_sf(data = cont_trend3, color = 'black', size = 0.2) +
geom_sf(data = pts, color = 'red', size = 0.5)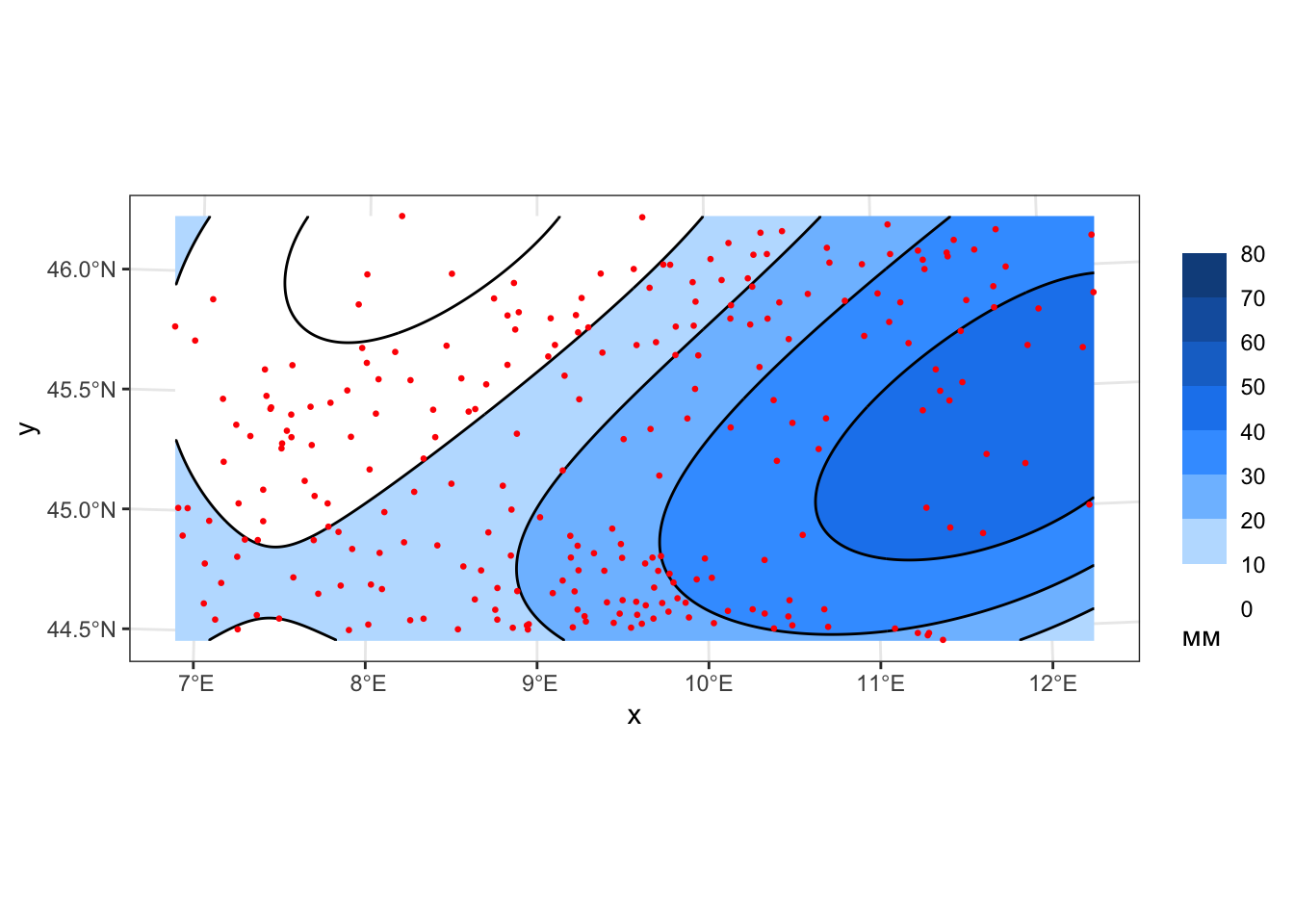
Наконец, рассмотрим полученные поверхности в трехмерном виде. Наклонная плоскость:
p = plot_ly(x = x, y = y,
z = px_grid$z_trend1,
type = "surface",
colors = rain_colors3d)
layout(p, scene = list(aspectratio = list(x = 1, y = 1, z = 0.3)))Поверхность 2-го порядка:
p = plot_ly(x = x, y = y,
z = px_grid$z_trend2,
type = "surface",
colors = rain_colors3d)
layout(p, scene = list(aspectratio = list(x = 1, y = 1, z = 0.3)))Поверхность 3-го порядка:
p = plot_ly(x = x, y = y,
z = px_grid$z_trend3,
type = "surface",
colors = rain_colors3d)
layout(p, scene = list(aspectratio = list(x = 1, y = 1, z = 0.3)))15.4.2 Локальный тренд
Метод построения локальной регрессии изначально был разработан для построения кривых регрессии в случае когда зависимость между переменными ведет себя сложным образом и не может быть описана в терминах традиционной линейной и нелинейной регрессии — глобальных методов.
Пусть даны измерения показателя в \(N\) исходных точках и задано число \(\alpha\) — сглаживающий параметр. Тогда аппроксимация показателя в каждом узле интерполяции получается путем построения поверхности тренда (см. выше) по \(\alpha N\) ближайшим исходным точкам. Как и в одномерном случае, близкие точки будут оказывать более сильное влияние на коэффициенты регрессии, чем удаленные.
Метод LOESS предоставляет широкие возможности настройки благодаря вариативности параметра сглаживания и степени регрессионного полинома.
Поскольку LOESS — это один из базовых методов регрессионного анализа, он входит в состав базового пакета stats. Для его использования нужно вначале инициализировать параметры локальной регрессии с помощью функции loess(). Параметры задаются в следующей форме:
- Формула, содержащая названия зависимой и независимых (координаты) переменной
- Набор данных, в котором содержатся значения переменных
- Степень полинома (
degree) - Сглаживающий параметр (
span) - Необходимость нормализации координат (приведения к квадратной области определения)
# ЛОКАЛЬНАЯ АППРОКСИМАЦИЯ (LOWESS)
# 0-я степень -------------------------------------------------------------
px_grid = px_grid |>
mutate(z_local0 = predict(loess(rain_24 ~ x + y, pts, degree = 0,
span = 0.07, normalize = FALSE), coords_grid) |> as('vector'),
z_local1 = predict(loess(rain_24 ~ x + y, pts, degree = 1,
span = 0.07, normalize = FALSE), coords_grid) |> as('vector'),
z_local2 = predict(loess(rain_24 ~ x + y, pts, degree = 2,
span = 0.07, normalize = FALSE), coords_grid) |> as('vector'))
# Визуализируем
cont_local0 = st_contour(px_grid['z_local0'],
breaks = rain_levels,
contour_lines = TRUE)
cont_local1 = st_contour(px_grid['z_local1'],
breaks = rain_levels,
contour_lines = TRUE)
cont_local2 = st_contour(px_grid['z_local2'],
breaks = rain_levels,
contour_lines = TRUE)
ggplot() +
geom_stars(data = cut(px_grid['z_local0'], breaks = rain_levels)) +
rain_legend +
coord_sf(crs = st_crs(pts)) +
geom_sf(data = cont_local0, color = 'black', size = 0.2) +
geom_sf(data = pts, color = 'red', size = 0.5)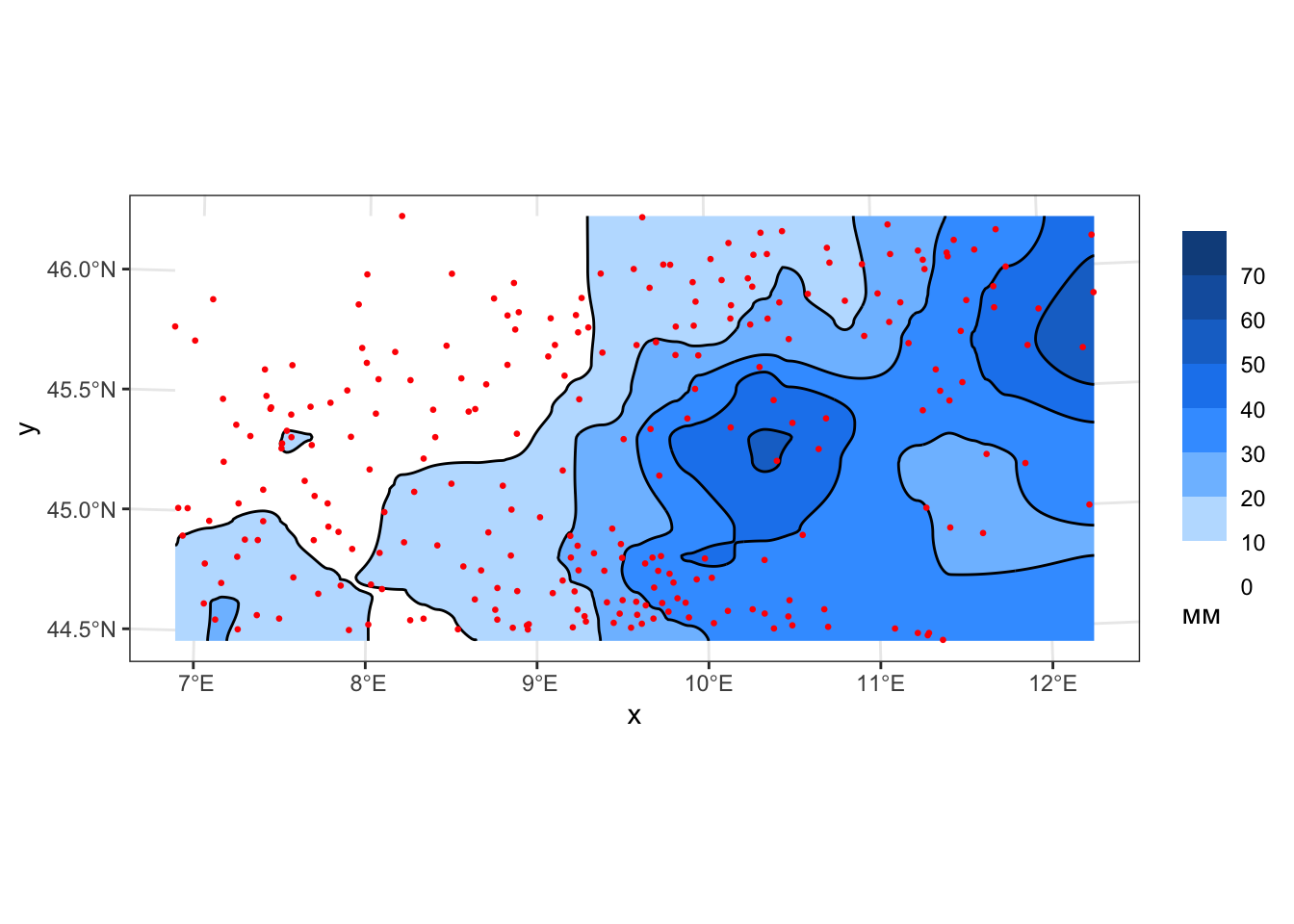
ggplot() +
geom_stars(data = cut(px_grid['z_local1'], breaks = rain_levels)) +
rain_legend +
coord_sf(crs = st_crs(pts)) +
geom_sf(data = cont_local1, color = 'black', size = 0.2) +
geom_sf(data = pts, color = 'red', size = 0.5)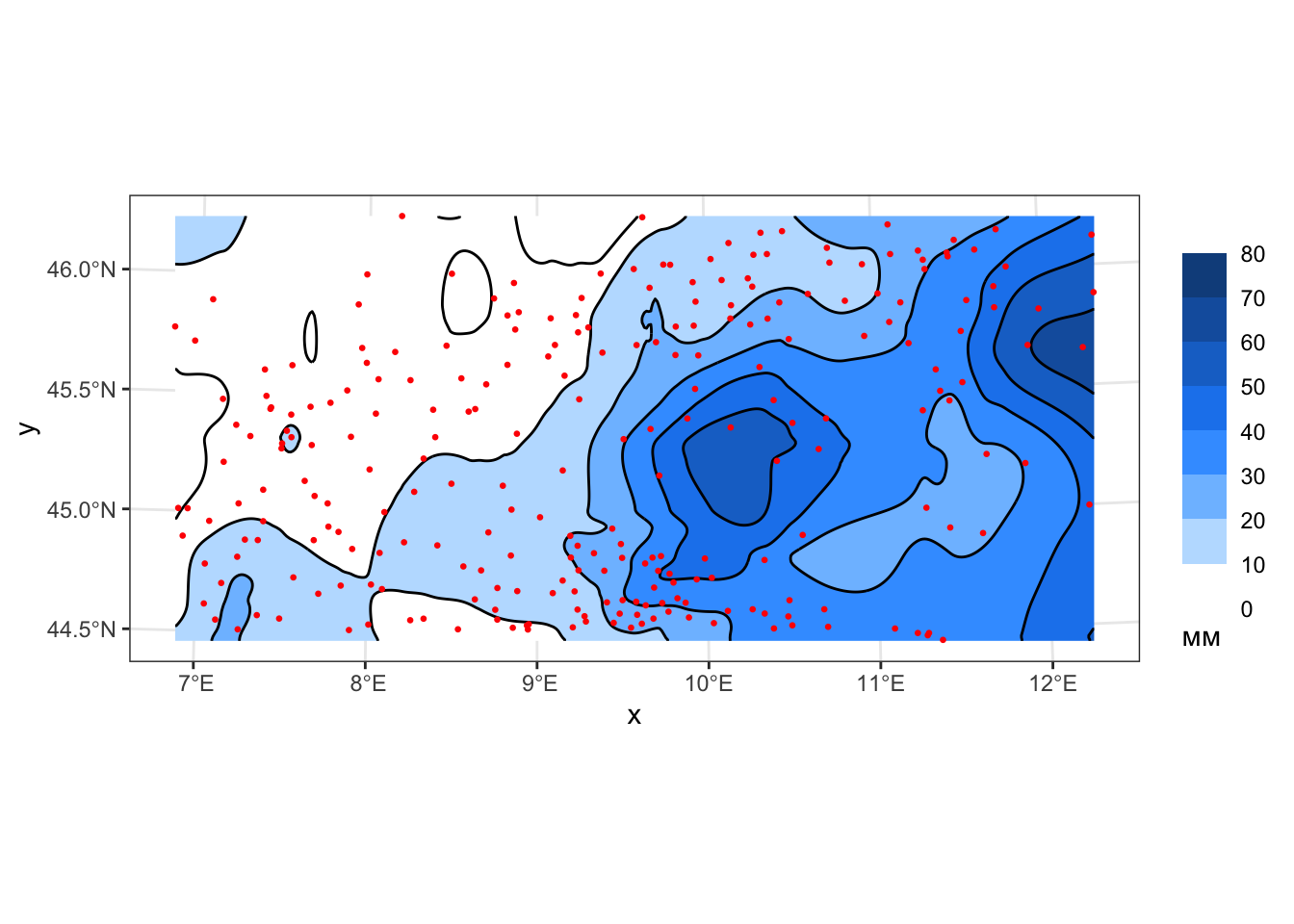
ggplot() +
geom_stars(data = cut(px_grid['z_local2'], breaks = rain_levels)) +
rain_legend +
coord_sf(crs = st_crs(pts)) +
geom_sf(data = cont_local2, color = 'black', size = 0.2) +
geom_sf(data = pts, color = 'red', size = 0.5)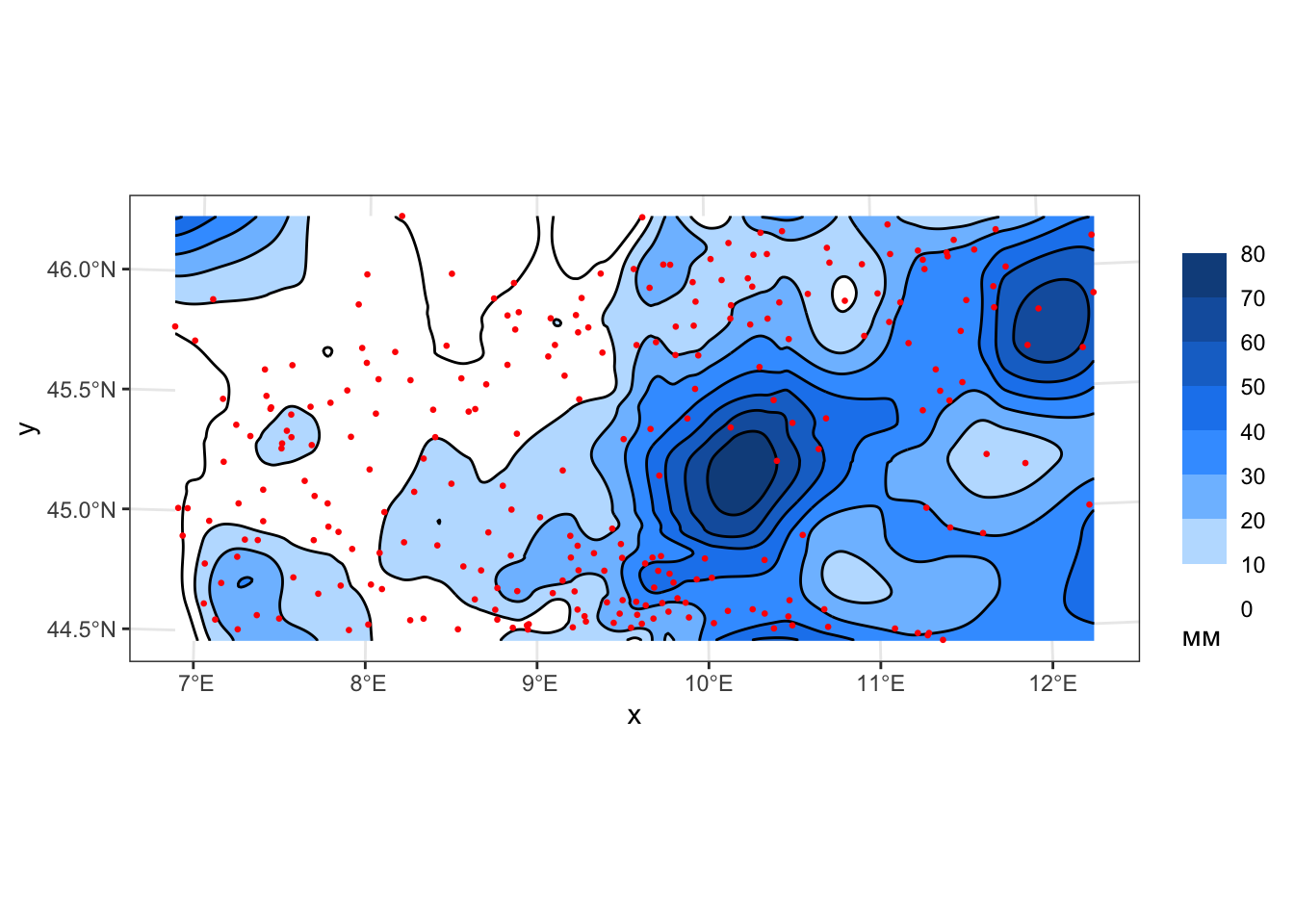
Рассмотрим результаты в 3D. Горизонтальная плоскость:
p = plot_ly(x = x, y = y,
z = px_grid$z_local0,
type = "surface",
colors = rain_colors3d)
layout(p, scene = list(aspectratio = list(x = 1, y = 1, z = 0.3)))Наклонная плоскость:
p = plot_ly(x = x, y = y,
z = px_grid$z_local1,
type = "surface",
colors = rain_colors3d)
layout(p, scene = list(aspectratio = list(x = 1, y = 1, z = 0.3)))Поверхность 2 порядка:
p = plot_ly(x = x, y = y,
z = px_grid$z_local2,
type = "surface",
colors = rain_colors3d)
layout(p, scene = list(aspectratio = list(x = 1, y = 1, z = 0.3)))Можно заметить, что с увеличением степени полинома поверхность все более точно аппроксимирует исходные данные — там, где достаточно большое количество исходных точек. В то же время, появляются нежелательные экстраполяции в приграничных областях, слабо обеспеченных измерениями, что можно наблюдать на последнем рисунке (степень = 2) в северо-западной части. Поэтому нельзя однозначно сказать, что более высокая степень обеспечивает лучшие результаты аппроксимации. Точность аппроксимации правильно регулировать не степенью полинома, а увеличением и уменьшением сглаживающего параметра альфа.
Рассмотрим это на примере линейной аппроксимации при \(\alpha = 0.05, 0.1, 0.2\):
px_grid = px_grid |>
mutate(z_local1_005 = predict(loess(rain_24 ~ x + y, pts, degree = 1,
span = 0.05, normalize = FALSE), coords_grid) |> as('vector'),
z_local1_01 = predict(loess(rain_24 ~ x + y, pts, degree = 1,
span = 0.1, normalize = FALSE), coords_grid) |> as('vector'),
z_local1_02 = predict(loess(rain_24 ~ x + y, pts, degree = 1,
span = 0.2, normalize = FALSE), coords_grid) |> as('vector'))
# Визуализируем
cont_local1_005 = st_contour(px_grid['z_local1_005'],
breaks = rain_levels,
contour_lines = TRUE)
cont_local1_01 = st_contour(px_grid['z_local1_01'],
breaks = rain_levels,
contour_lines = TRUE)
cont_local1_02 = st_contour(px_grid['z_local1_02'],
breaks = rain_levels,
contour_lines = TRUE)
ggplot() +
geom_stars(data = cut(px_grid['z_local1_005'], breaks = rain_levels)) +
rain_legend +
coord_sf(crs = st_crs(pts)) +
geom_sf(data = cont_local1_005, color = 'black', size = 0.2) +
geom_sf(data = pts, color = 'red', size = 0.5)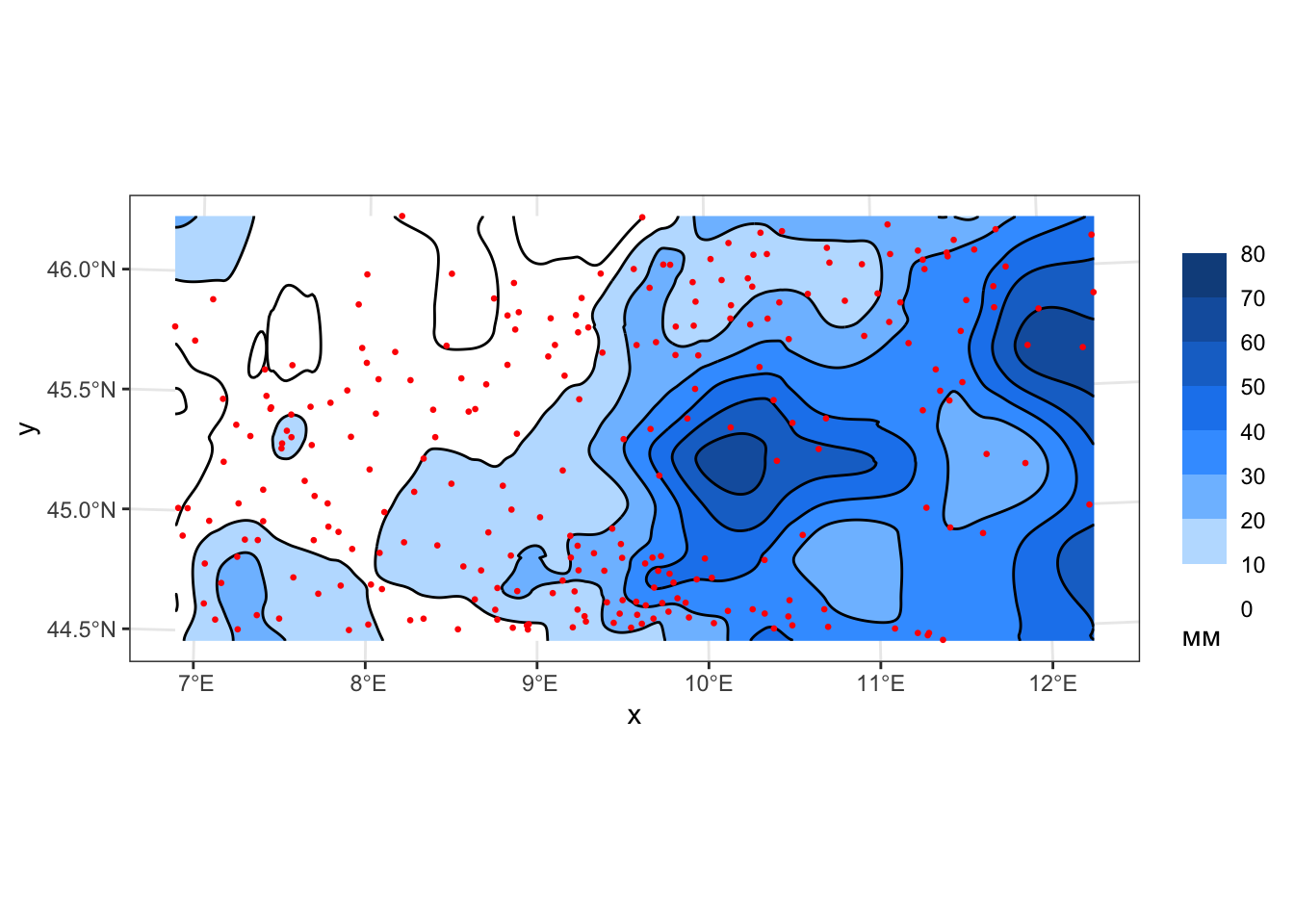
ggplot() +
geom_stars(data = cut(px_grid['z_local1_01'], breaks = rain_levels)) +
rain_legend +
coord_sf(crs = st_crs(pts)) +
geom_sf(data = cont_local1_01, color = 'black', size = 0.2) +
geom_sf(data = pts, color = 'red', size = 0.5)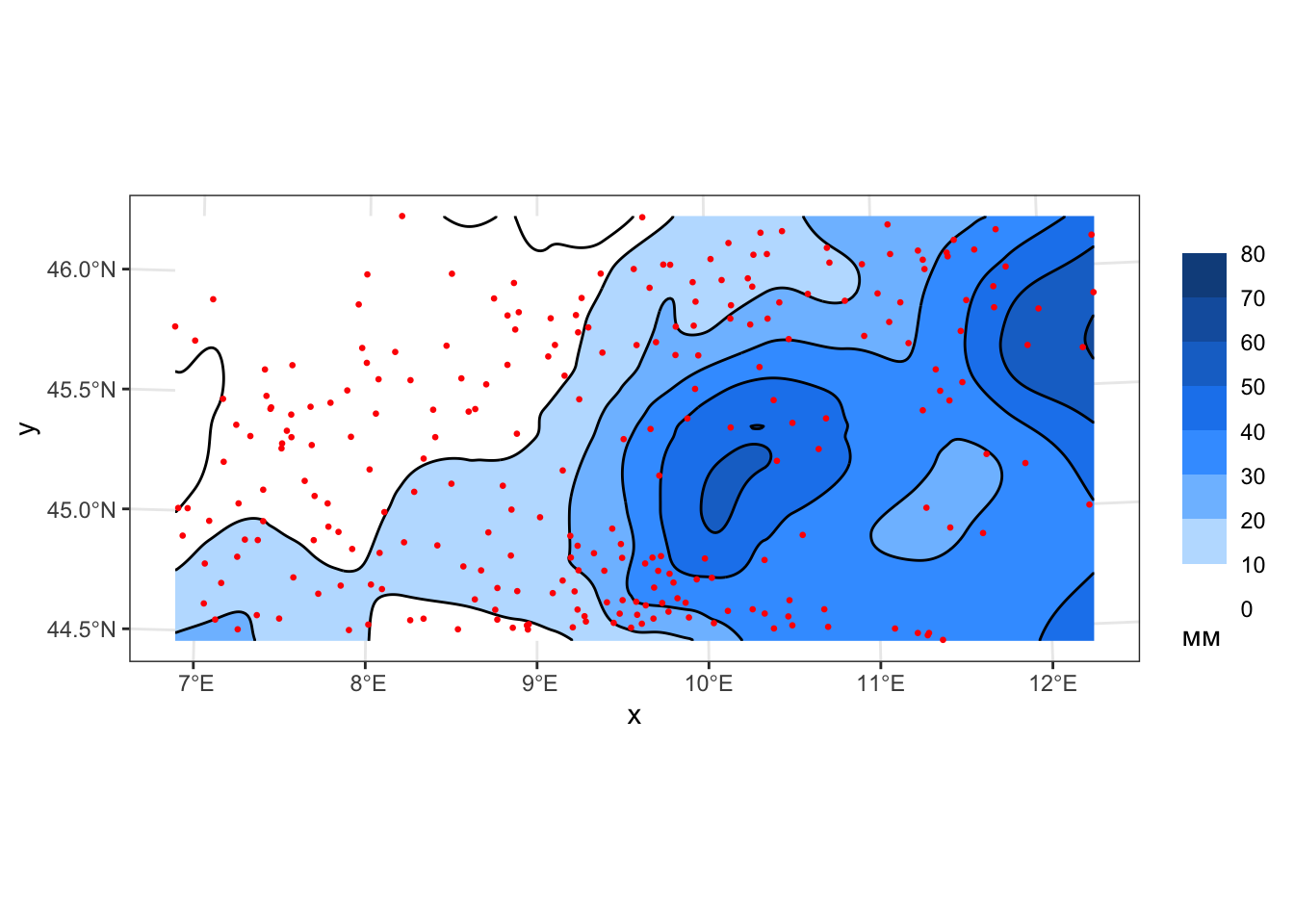
ggplot() +
geom_stars(data = cut(px_grid['z_local1_02'], breaks = rain_levels)) +
rain_legend +
coord_sf(crs = st_crs(pts)) +
geom_sf(data = cont_local1_02, color = 'black', size = 0.2) +
geom_sf(data = pts, color = 'red', size = 0.5)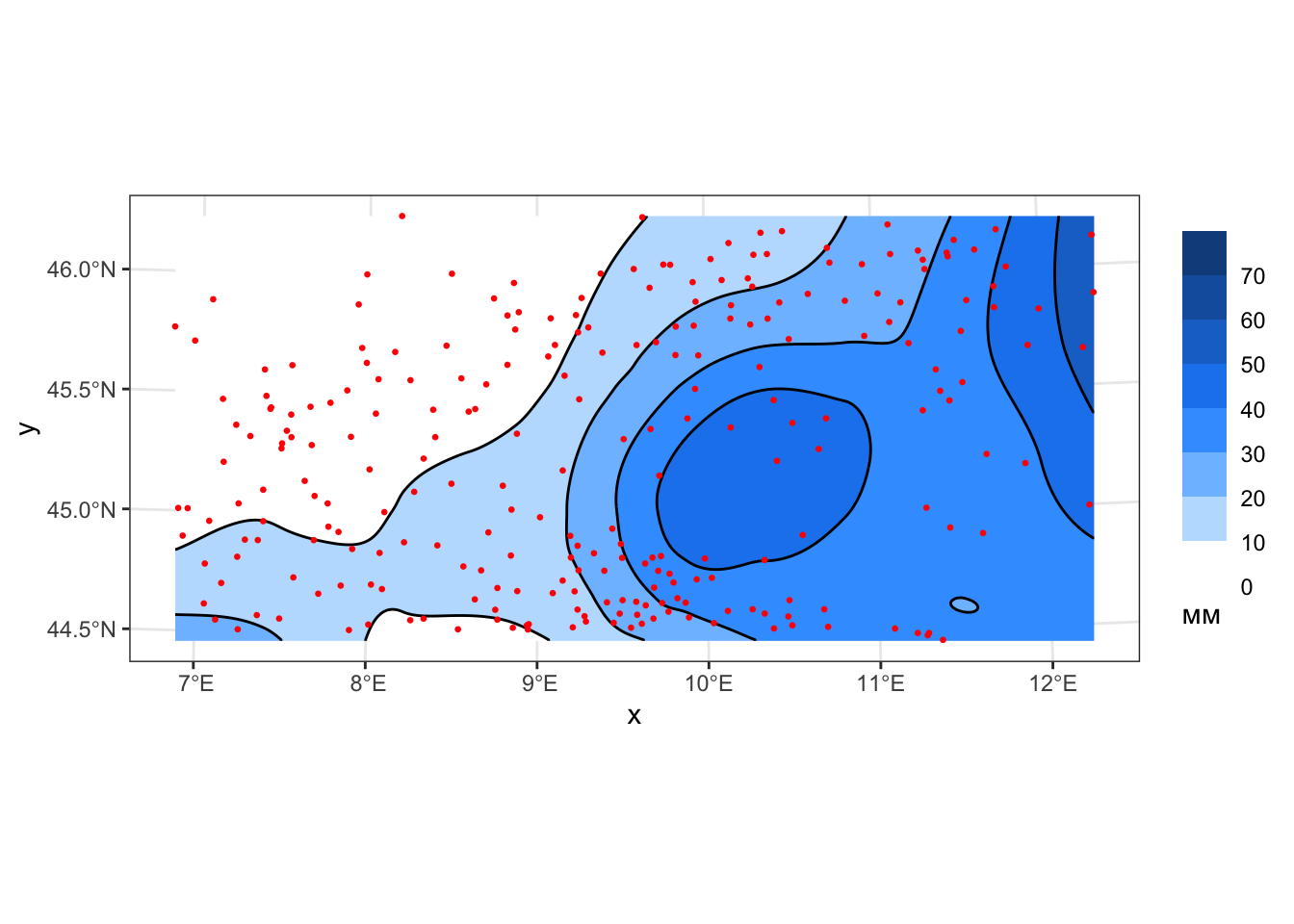
Сравниваем результаты в трехмерном виде. Горизонтальная плоскость:
p = plot_ly(x = x, y = y,
z = px_grid$z_local1_005,
type = "surface",
colors = rain_colors3d)
layout(p, scene = list(aspectratio = list(x = 1, y = 1, z = 0.3)))Наклонная плоскость:
p = plot_ly(x = x, y = y,
z = px_grid$z_local1_01,
type = "surface",
colors = rain_colors3d)
layout(p, scene = list(aspectratio = list(x = 1, y = 1, z = 0.3)))Поверхность 2 порядка:
p = plot_ly(x = x, y = y,
z = px_grid$z_local1_02,
type = "surface",
colors = rain_colors3d)
layout(p, scene = list(aspectratio = list(x = 1, y = 1, z = 0.3)))15.5 Краткий обзор
Для просмотра презентации щелкните на ней один раз левой кнопкой мыши и листайте, используя кнопки на клавиатуре:
Презентацию можно открыть в отдельном окне или вкладке браузере. Для этого щелкните по ней правой кнопкой мыши и выберите соответствующую команду.
15.6 Контрольные вопросы и упражнения
15.6.1 Вопросы
- Сформулируйте отличие интерполяционных и аппроксимационных методов восстановления поверхностей по данным в нерегулярно расположенных точках.
- Какой метод интерполяции подходит для работы с категориальными (качественными) данными?
- При каких условиях в методе интерполяции на основе триангуляции возможна оценка величины за пределами выпуклой оболочки исходного множества точек?
- Назовите основной недостаток метода обратно взвешенных расстояний.
- Каким требованиям должна удовлетворять радиальная базисная функция?
- Если дана функция, являющаяся радиальной базисной, можно ли в качестве таковой использовать обратную к ней? Как это реализуется математически?
- В каком методе интерполяции используются сплайны с натяжением?
- Сформулируйте основные принципы восстановления поверхности методом иерархических базисных сплайнов.
- Полиномы каких степеней обычно используются в задачах аппроксимации на практике?
- Каким образом реализуется метод локальной регрессии в приложении к пространственным данным?
- В чем заключается отличие экстенсивных и интенсивных пространственных переменных?
- Перечислите пакеты программной среды R, которые можно использовать для восстановления поверхностей по данным в нерегулярно расположенных точках.
- Какие функции R позволяют построить регулярную сетку? Как преобразовать эту сетку в растр?
- Изложите последовательность действий, необходимую для трехмерной визуализации поверхности средствами библиотеки plotly.
15.6.2 Упражнения
Загрузите данные дрейфующих буев ARGO на акваторию Северной Атлантики за 30 января 2010 года. Постройте поля распределения солености и температуры всеми перечисленными в лекции методами с размером ячейки 50 км. Визуализируйте их средствами tmap и сравните результаты. Какой метод интерполяции дает, на ваш взгляд, более правдоподобный результат?
Подсказка: перед построением сетки интерполяции трансформируйте данные в проекцию Меркатора. Чтобы полученное поле распределения покрывало только акваторию, маскируйте полученный растр с использованием слоя ocean из набора данных Natural Earth. Перед выполнением маскирования преобразуйте мультиполигон в обычные полигоны (в противном случае маскирование отработает некорректно).
| Самсонов Т.Е. Визуализация и анализ географических данных на языке R. М.: Географический факультет МГУ, 2023. DOI: 10.5281/zenodo.901911 |